
La cdc data sert à transformer une base transactionnelle en flux de changements exploitables. Concrètement, on suit les insertions, les mises à jour et les suppressions pour alimenter un entrepôt, synchroniser un SI ou fiabiliser une migration sans recopier toute la base à chaque fois. Je vais clarifier ce que fait réellement la CDC, comment elle s’insère dans une architecture de données, quelles méthodes de capture choisir et où se trouvent les pièges qui coûtent du temps en production.
L’essentiel à garder avant de choisir une architecture CDC
- La CDC capture les changements, pas des extractions complètes répétées.
- La méthode la plus robuste s’appuie le plus souvent sur le journal de transaction.
- Un bon schéma commence presque toujours par un snapshot initial puis un rattrapage des deltas.
- Les usages les plus rentables concernent la migration, la synchronisation et l’analytique quasi temps réel.
- Le vrai sujet en production, ce sont la latence, la croissance du journal, la rétention et la qualité des consommateurs.
Ce que recouvre la capture de données modifiées
Quand je parle de CDC, je parle d’un mécanisme qui observe une source de vérité et n’en extrait que les événements utiles: création, modification, suppression. La logique est simple sur le papier, mais elle change beaucoup de choses dans un système d’information, parce qu’on ne traite plus une base comme un bloc figé à recopier, mais comme un flux continu d’états à propager.
La différence avec un chargement batch classique est nette. Un ETL nocturne recopie souvent tout ou partie du dataset à heure fixe; la CDC, elle, réduit la quantité de données déplacées et garde la cible beaucoup plus fraîche. Dans la pratique, cela permet d’avoir des tableaux de bord plus réactifs, des répliques mieux synchronisées et des migrations moins risquées.
Je précise souvent un point qui évite bien des malentendus: la CDC transporte les changements, mais elle ne remplace pas la logique de modélisation côté cible. Si l’entrepôt doit conserver l’historique d’un client, d’un produit ou d’un contrat, c’est ensuite au modèle cible de décider comment stocker cet historique. La CDC alimente le moteur; elle ne décide pas à elle seule de la forme finale des données. C’est précisément ce passage du transport à la modélisation qui justifie de regarder ensuite le fonctionnement interne du flux.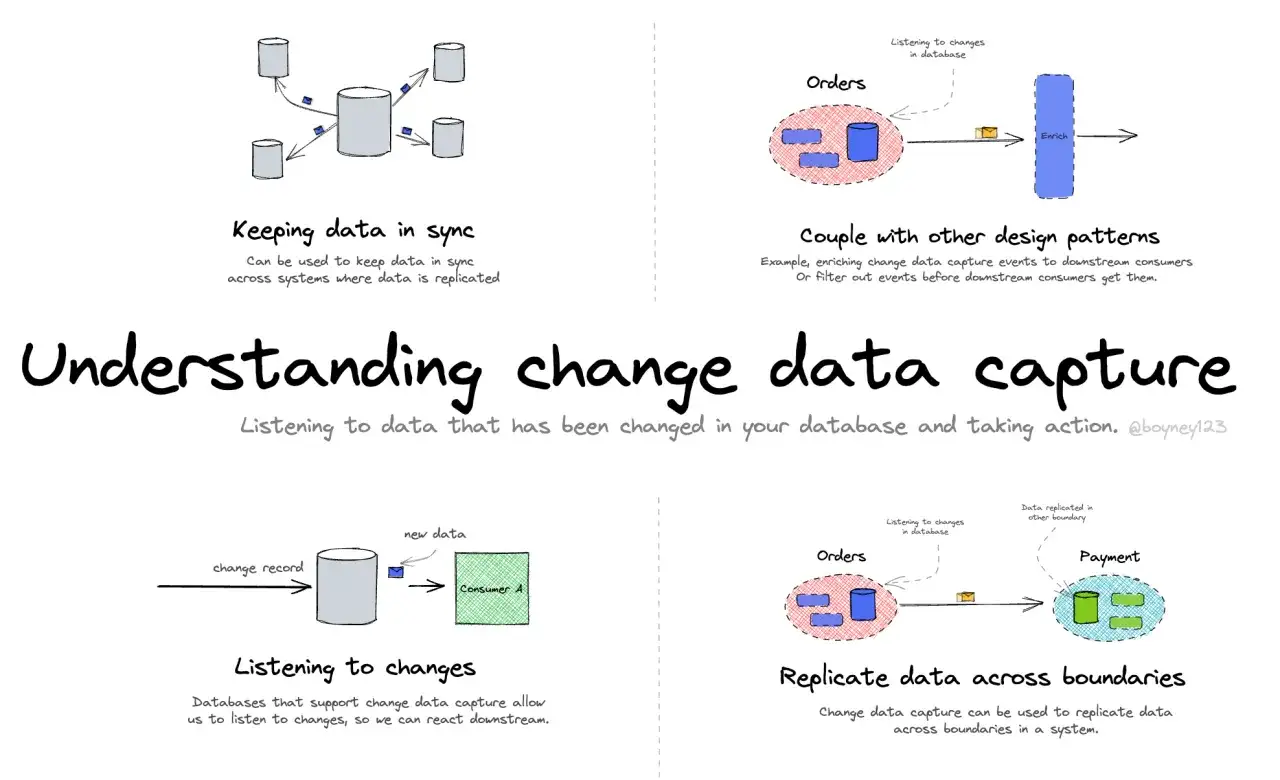
Comment le flux CDC circule dans un SI
La version la plus propre d’une chaîne CDC suit presque toujours le même schéma: je pars d’un snapshot cohérent, je charge cette base initiale dans la cible, puis je démarre la lecture des changements à partir du bon point du journal. Cette approche évite de perdre les lignes modifiées pendant le chargement initial et elle reste valable même sur de gros volumes.
- Le point de départ est le journal de transaction de la base source. Selon le moteur, on parlera de WAL, de redo log ou de binlog, mais l’idée reste la même: enregistrer les opérations dans un ordre fiable.
- Le snapshot initial sert à remplir la cible une première fois. Sans lui, on ne capture que les changements futurs et on perd l’état de départ.
- Le rattrapage commence à un identifiant précis du journal, souvent un LSN, c’est-à-dire un repère de position dans le flux. Ce repère permet de reprendre sans doublon ni trou après une coupure.
Dans une architecture saine, les consommateurs du flux doivent aussi être idempotents, c’est-à-dire capables de rejouer deux fois le même événement sans casser l’état final. Je préfère toujours insister sur ce point, parce qu’un pipeline CDC n’est jamais seulement un sujet de capture; c’est aussi un sujet de reprise, de tolérance aux erreurs et de cohérence entre plusieurs systèmes. Une fois ce mécanisme compris, le vrai choix devient: quelle méthode de capture convient à mon contexte technique?
Quelle méthode de capture choisir selon la base
Je vois souvent trois familles de CDC. Elles ne se valent pas toutes, et je ne les choisirais pas pour les mêmes raisons. Le meilleur choix dépend du moteur de base, de la charge d’écriture, du niveau de contrôle que l’on a sur le SI et de la précision attendue sur les suppressions ou les changements rapides.
| Approche | Principe | Atouts | Limites | Quand je la choisis |
|---|---|---|---|---|
| Log-based | Lecture du journal de transaction pour récupérer les INSERT, UPDATE et DELETE | Peu intrusif, précis, adapté aux gros volumes | Demande un moteur compatible et une bonne gestion de la reprise | Quand je veux la meilleure combinaison entre robustesse et performance |
| Trigger-based | Des déclencheurs écrivent les changements dans des tables tampons | Assez facile à comprendre sur certains systèmes anciens | Ajoute de la charge sur le chemin d’écriture et complique la maintenance | Quand le journal n’est pas exploitable ou que la base est trop contrainte |
| Timestamp-based | Lecture périodique des lignes modifiées après une date de référence | Simple à implémenter pour un cas peu critique | Moins fiable, plus lent, et souvent insuffisant pour les suppressions | Quand le besoin est modeste et que je peux accepter des limites nettes |
Si je dois trancher sans contrainte particulière, je pars presque toujours sur une solution basée sur le journal. Les déclencheurs ne sont pas “mauvais”, mais ils déplacent le coût vers les écritures, ce qui devient vite sensible sur un système transactionnel chargé. Quant aux approches à base de timestamp, elles rendent service pour une synchronisation simple, mais elles montrent vite leurs limites dès qu’on veut de la fiabilité, des suppressions bien prises en compte ou une vraie reprise après incident. Le bon choix technique prend alors tout son sens quand on le relie aux cas d’usage réels.
Les usages qui justifient vraiment la mise en place
La CDC n’est pas utile juste parce qu’elle est moderne. Elle prend de la valeur quand on veut résoudre un problème d’exploitation concret, mesurable, parfois douloureux. Dans les projets que je juge solides, elle sert généralement à quatre familles d’usages.
- La migration à chaud: on copie d’abord la base, puis on rattrape les changements jusqu’au basculement. C’est la meilleure façon de réduire le temps d’indisponibilité.
- La réplication opérationnelle: une base secondaire, un cache ou un moteur de recherche doivent rester proches de la source sans rechargements massifs.
- L’analytique quasi temps réel: un tableau de bord commercial, financier ou logistique gagne énormément quand il n’attend plus le batch de la nuit.
- La synchronisation inter-applications: ERP, CRM, support client et data platform doivent souvent partager une vision cohérente des mêmes entités.
- Les flux pour l’IA et le machine learning: des données fraîches améliorent la qualité des jeux d’entraînement et réduisent les écarts entre le réel et ce que l’on teste.
Le gain le plus visible n’est pas toujours la vitesse brute, mais la réduction des écarts de données. Quand un ordre, une facture ou une fiche client circule vite et proprement, tout le reste du SI travaille mieux. Cela dit, ces bénéfices ne viennent pas gratuitement, et les limites doivent être regardées avant de mettre la CDC en production.
Les limites qu’il faut anticiper avant la production
La CDC donne une impression de fluidité, mais elle impose une discipline technique assez stricte. Le premier risque que je surveille est la pression sur le journal de transaction: si les transactions restent ouvertes trop longtemps ou si le consommateur prend du retard, le journal grossit et la base peut manquer d’espace. Dans Azure SQL Database, par exemple, la capture tourne automatiquement toutes les 20 secondes et le nettoyage chaque heure; ce genre de cadence montre bien qu’on reste dans un mécanisme proche du temps réel, pas dans une promesse magique d’instantanéité absolue.- La latence peut augmenter si la source écrit beaucoup ou si le consommateur est lent.
- La croissance du log devient un vrai sujet quand la rétention est trop longue ou que la reprise est mal conçue.
- Les changements de schéma ne sont pas toujours gratuits: une colonne ajoutée, renommée ou supprimée peut casser un pipeline mal préparé.
- La gestion des caractères mérite attention: des différences de collation ou un mauvais choix entre `varchar` et `nvarchar` peuvent introduire des incohérences sur des données non ASCII.
- Les objets réservés posent parfois problème: un schéma ou un utilisateur nommé `cdc` peut bloquer l’activation sur certains moteurs.
J’ajoute un autre piège que l’on sous-estime souvent: le consommateur est aussi important que le capteur. Si la cible n’est pas idempotente, si elle ne gère pas les doublons ou si elle ne sait pas rejouer un lot de changements après incident, la CDC perd une grande partie de son intérêt. C’est pour cette raison que la réussite d’un projet repose moins sur l’outil choisi que sur la manière de l’exploiter.
Les réglages qui évitent les surprises en production
Quand je mets en place une chaîne CDC, je commence petit et je verrouille d’abord la mécanique, pas l’ambition. Je préfère un premier périmètre limité, un monitoring clair et des règles de reprise simples plutôt qu’un déploiement large qui semble élégant mais que personne ne sait corriger à 2 h du matin.
- Je pars d’une table critique seulement, pas de tout le SI. Cela permet de mesurer la latence, la charge et la qualité des événements dans un cadre maîtrisé.
- Je combine snapshot et catch-up dès le début. Sans cette séquence, les données historiques et les changements récents risquent de diverger.
- Je rends les consommateurs idempotents. C’est la meilleure assurance contre les doublons, les redémarrages et les reprises partielles.
- Je définis une rétention explicite pour les événements, les journaux et les tables techniques. La CDC a besoin de place et d’une politique de nettoyage claire.
- Je surveille la dérive du log, la latence de capture, les erreurs de schéma et le débit de reprise. Sans ça, on découvre les problèmes trop tard.
- Je filtre et je masque les données sensibles quand c’est nécessaire. La CDC ne dispense jamais du RGPD ni de la minimisation des copies internes.
À ce stade, la bonne question n’est plus “faut-il faire de la CDC ?”, mais “comment en faire une brique de cohérence du SI sans multiplier les copies inutiles”. C’est là que la technique devient réellement utile: elle relie la base source, les usages métiers et la gouvernance des données sans forcer le système à tout recalculer en permanence.
Ce que je verrouille avant d’ouvrir la CDC à tout le système
Si je devais résumer l’approche en une règle, je dirais ceci: la CDC doit réduire la friction, pas déplacer le chaos. Elle fonctionne très bien quand la source est stable, que la cible sait rejouer les événements et que l’équipe accepte une logique d’exploitation un peu plus rigoureuse qu’un simple export planifié.
Le bon réflexe, en 2026 comme avant, consiste à traiter la CDC comme une infrastructure de confiance: on surveille, on documente, on teste les reprises et on garde des limites de responsabilité nettes entre capture, transport et consommation. C’est cette séparation qui évite les architectures fragiles et les fausses promesses de temps réel partout, tout le temps.
Quand ces garde-fous sont en place, la capture de données modifiées devient une vraie brique d’architecture: elle raccourcit les délais, améliore la cohérence entre systèmes et simplifie les migrations. C’est précisément le genre de mécanisme qui mérite d’être pensé tôt, avant que le SI ne soit trop complexe pour absorber des corrections improvisées.