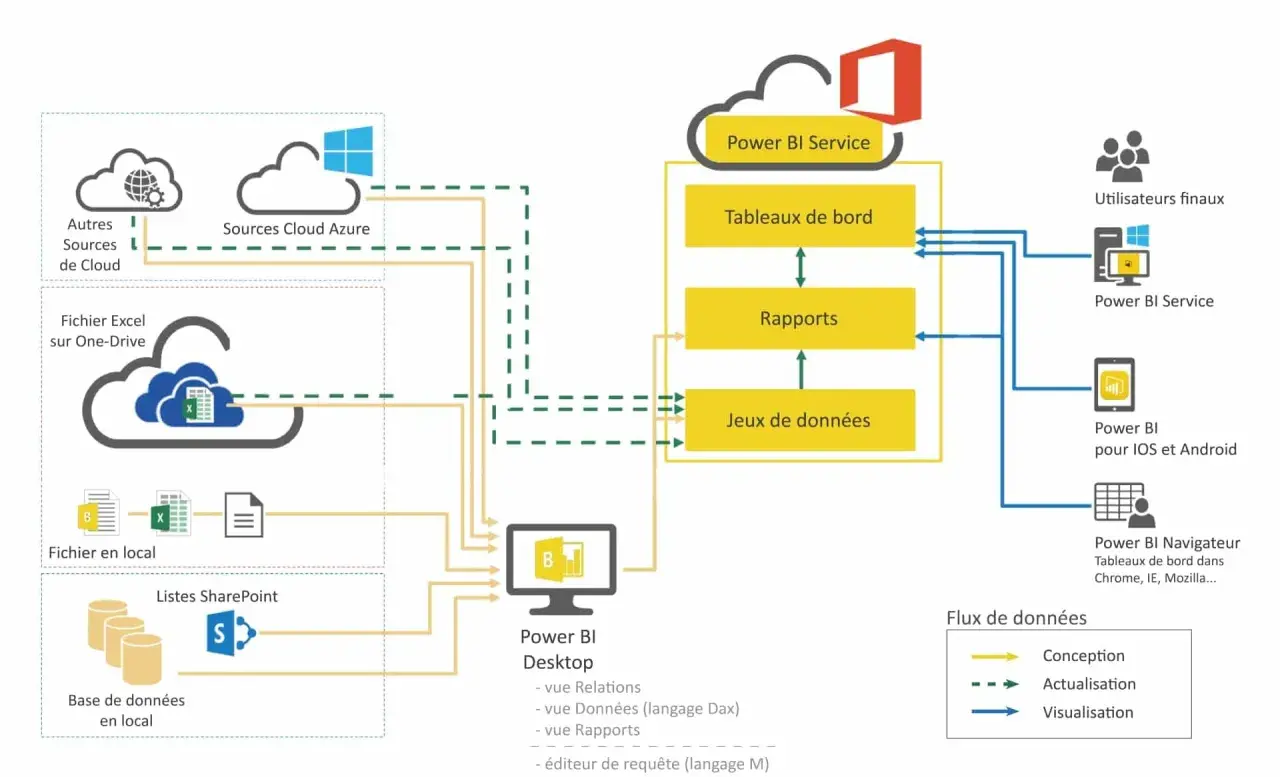
Relier Power BI à Azure change surtout la manière de concevoir un système de reporting: on décide où résident les données, à quel rythme elles se mettent à jour et quel niveau de charge on accepte côté source. Dans un projet bien pensé, cette chaîne évite les copies inutiles, réduit les délais de publication et garde les indicateurs crédibles pour la DSI comme pour les métiers. Je vais donc traiter le sujet comme un vrai choix d’architecture, pas comme un simple connecteur à configurer.
Les points clés à garder en tête avant de brancher Power BI sur Azure
- Power BI sert de couche de restitution, Azure de couche de stockage, de calcul ou d’ingestion.
- Azure SQL est le point d’entrée le plus simple quand la donnée est relationnelle et bien structurée.
- Synapse, ADLS Gen2 et Databricks prennent le relais quand les volumes, les formats ou la transformation deviennent plus ambitieux.
- Import favorise la vitesse, DirectQuery favorise la fraîcheur, et le modèle composite sert à combiner les deux.
- En environnement d’entreprise, la sécurité, la région Azure, la passerelle et la capacité comptent autant que le visuel final.
- Les gains durables viennent surtout d’un bon modèle sémantique et d’une vraie stratégie de rafraîchissement.
Ce que change réellement l’association Power BI et Azure
Je vois souvent des projets qui commencent par un connecteur, alors qu’ils devraient commencer par un flux de données. Avec Azure et Power BI, l’enjeu n’est pas seulement de visualiser plus vite: c’est de choisir où vivent les données, qui les transforme, à quelle fréquence elles bougent et qui a le droit de les consommer.
Dans une DSI, le bon montage évite les copies inutiles, limite les goulots d’étranglement et garde les tableaux de bord crédibles. Le vrai intérêt d’Azure est de donner de la place au SI: stockage massif, calcul scalable, options de sécurité plus fines et données mieux partitionnées. Power BI, lui, transforme cela en analyse lisible. C’est ce choix d’architecture qui permet ensuite de trancher entre Azure SQL, Synapse, ADLS ou Databricks.
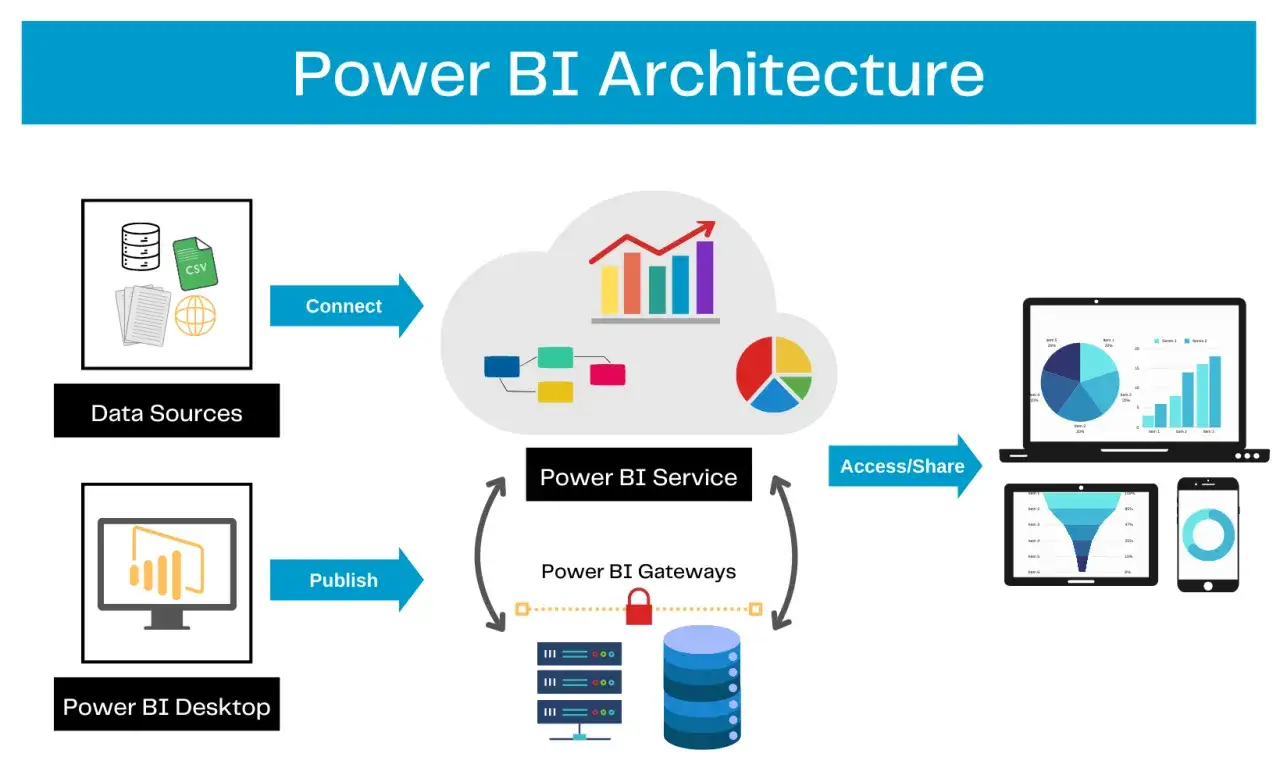
Les sources Azure à privilégier selon le besoin
Quand je dois cadrer un projet, je commence par la nature de la donnée plutôt que par l’outil. Une donnée transactionnelle ne se traite pas comme un lac brut, et un entrepôt historique ne se consomme pas comme une API opérationnelle.
| Source Azure | Quand je la privilégie | Ce qu’elle apporte | Limites à connaître |
|---|---|---|---|
| Azure SQL Database | Reporting opérationnel, KPI métier, données relationnelles propres | Connexion simple, DirectQuery ou Import, bon SSO, faible complexité d’exploitation | Moins adaptée si l’historique devient massif ou si le modèle analytique se complexifie trop |
| Azure Synapse Analytics | Entrepôt de données, volumes importants, analyses multi-sources | Bon point d’appui pour les scénarios analytiques à grande échelle | Le connecteur direct dans le service Power BI n’est plus disponible; je passe par Power BI Desktop |
| Azure Data Lake Storage Gen2 | Données brutes, staging, couches d’atterrissage, fichiers variés | Grande souplesse de stockage, utile dans une architecture lake ou medallion | Le schéma doit être pensé en amont; le connecteur est plus sensible aux chemins et à l’authentification |
| Azure Databricks | Transformations lourdes, lakehouse, préparation avancée des données | Très bon pour industrialiser les traitements et garder une séparation nette entre préparation et restitution | Le bon fonctionnement dépend beaucoup du pipeline, de la gouvernance et de la version du connecteur |
Azure SQL Database est le point d’entrée le plus simple quand la donnée est relationnelle, bien structurée et que l’on veut publier vite. Azure Synapse Analytics prend le relais pour des volumes plus larges ou des besoins d’entrepôt; la documentation Microsoft précise que, pour ce service, la voie la plus fiable consiste à construire le modèle dans Power BI Desktop puis à publier dans le service.
Azure Data Lake Storage Gen2 est utile quand la donnée arrive en fichiers ou en couches de préparation, mais il faut accepter plus de rigueur dans la structuration. Le connecteur fonctionne mieux quand on pointe sur le conteneur et non sur un fichier ou un sous-dossier isolé. Databricks, enfin, devient intéressant dès qu’il faut industrialiser des transformations lourdes ou orchestrer un vrai lakehouse.
Une fois la source choisie, il faut décider si Power BI doit copier les données ou interroger Azure en direct.
Décider entre Import, DirectQuery et modèle composite
Le débat se résume souvent à une fausse opposition entre fraîcheur et performance. En pratique, tout dépend du volume, du nombre d’utilisateurs et du temps de réponse attendu.
| Mode | Ce qu’il fait | Avantages | Quand je le choisis | Limites |
|---|---|---|---|---|
| Import | Les données sont chargées dans le modèle sémantique | Visuels rapides, DAX confortable, excellente stabilité côté lecture | Analyse historique, reporting interne, besoin de fluidité | Il faut organiser le refresh et accepter une légère latence |
| DirectQuery | Power BI envoie les requêtes à la source au moment de la consultation | Les données restent à la source, pas de duplication, fraîcheur immédiate ou quasi immédiate | Reporting opérationnel, données qui changent souvent, base bien optimisée | Tout dépend des performances de la source et du schéma |
| Modèle composite | Combine Import et DirectQuery dans un même modèle | Très bon compromis entre historique et données chaudes | Cas hybrides, tables de faits très actives, besoin de flexibilité | Plus complexe à concevoir, tester et maintenir |
Pour Azure SQL, l’approche DirectQuery est intéressante quand l’équipe connaît déjà le schéma, les tables et les contraintes de la base. Les requêtes repartent vers la source pendant la navigation, ce qui permet de garder la donnée là où elle vit vraiment. C’est solide si la base est bien indexée; c’est beaucoup moins confortable si l’on a laissé trop de logique métier côté rapport.
Le modèle composite vaut surtout pour les cas hybrides: historique en import, données récentes en DirectQuery, ou tables métiers importées avec une table de faits vivante. C’est la bonne réponse quand un seul mode devient un compromis trop brutal.
Une fois ce choix posé, la question suivante n’est plus technique seulement: elle touche à la sécurité, au réseau et à la gouvernance.
Sécuriser l’accès sans compliquer la vie des équipes
Dans un contexte de DSI française, je traite toujours trois sujets en même temps: l’identité, le réseau et la capacité. L’identité passe généralement par Microsoft Entra ID; sur Azure SQL et certains scénarios DirectQuery, le SSO peut remonter jusqu’à la source, ce qui évite de casser la chaîne de sécurité entre l’outil de restitution et la base.
Le réseau, lui, devient critique dès qu’une source n’est pas publiquement accessible. Si la donnée reste on-premises ou dans un périmètre privé, la passerelle reste le bon outil. Le mode standard est celui que je recommande pour les scénarios partagés, et le cluster devient vite pertinent dès qu’on cherche de la haute disponibilité. Le mode personnel ne me sert que dans des cas très individuels.
Je vérifie aussi les cas inter-locataires sur Azure Data Lake Storage Gen2, parce qu’un rafraîchissement qui fonctionne en test peut bloquer en production si l’authentification ou le locataire ne sont pas alignés. Ce n’est pas spectaculaire, mais c’est typiquement le genre de détail qui bloque un go-live.
La capacité et les licences ne doivent pas être traitées en bout de chaîne. Pour collaborer à l’échelle de l’entreprise, Microsoft indique qu’il faut une capacité F ou P et au moins une licence par utilisateur selon le scénario. Si vous prévoyez du partage large ou de l’embarqué, budgetez cela dès la conception, pas au moment de la mise en production.
Enfin, alignez région Azure, tenant Power BI et contraintes de résidence des données. Sur Synapse, cela peut même jouer sur les frais d’egress; si la région est la même, la sortie de données peut être évitée. C’est typiquement le genre de détail qui paraît secondaire jusqu’au jour où la facture arrive.
Une fois l’accès cadré, la vraie bataille se joue sur le modèle et le rafraîchissement.
Garder des performances stables quand les volumes montent
Je vois beaucoup de projets échouer non pas à cause du cloud, mais à cause d’un modèle trop plat ou d’un refresh trop ambitieux. Power BI recommande les principes de star schema: une table de faits, des dimensions bien séparées, et des relations simples qui filtrent proprement. Ce n’est pas un détail académique; c’est ce qui rend les visuels plus rapides et les mesures plus lisibles.
Quand les données grossissent, j’essaie de déplacer le gros du travail vers la préparation en amont. Si la source est relationnelle, l’incremental refresh est souvent le meilleur levier: on ne recharge que les partitions récentes, et le service gère le reste. La documentation Microsoft précise aussi que cette stratégie fonctionne particulièrement bien avec SQL Database et Azure Synapse, et qu’en Pro le temps de refresh reste limité à 2 heures, contre 5 heures dans une capacité Premium. Ces chiffres changent la manière de dimensionner le pipeline.
Autre règle simple: si vous devez jongler avec des millions de lignes, je préfère une source propre et un modèle bien pensé à un empilement de transformations lourdes dans Power BI Desktop. Le query folding, c’est-à-dire la capacité à pousser les filtres jusqu’à la source, devient alors décisif. S’il casse, le modèle paie la note; s’il tient, le refresh devient beaucoup plus supportable.
En pratique, le meilleur signal n’est pas le nombre de visuels, mais le temps nécessaire pour répondre à une question simple sur une table de faits. C’est à ce moment-là qu’on voit si le problème vient du stockage, du schéma ou du mode de connexion.
Les erreurs les plus coûteuses que je vois en projet
- Connecter directement le rapport à la mauvaise couche. Un fichier brut dans ADLS n’est pas un modèle analytique.
- Utiliser DirectQuery partout. Si la source n’est pas parfaitement indexée, c’est elle qui ralentit tout.
- Oublier que le connecteur Synapse direct dans le service n’est plus disponible et que le passage par Power BI Desktop reste la voie normale.
- Pointer Azure Data Lake Storage Gen2 sur un fichier ou un sous-dossier au lieu du conteneur, puis perdre du temps à diagnostiquer un problème qui est en réalité structurel.
- Installer une passerelle personnelle pour un usage d’équipe, alors qu’un mode standard ou un cluster aurait évité un futur blocage.
- Ignorer la région Azure et les contraintes réseau, puis découvrir des délais ou des coûts inattendus au moment de la montée en charge.
La plupart de ces erreurs ne viennent pas d’un manque de compétence; elles viennent d’un mauvais ordre de décision. On commence par la visualisation alors qu’il faudrait commencer par la couche de données et le cycle de vie du modèle.
Ma règle simple pour démarrer sans se tromper
Si je dois garder une seule grille de lecture, elle tient en quatre cas. Donnée relationnelle et stable: je pars sur Azure SQL avec Import ou DirectQuery selon la fraîcheur attendue. Entrepôt large ou historique lourd: je privilégie Synapse ou une couche analytique dédiée, puis un modèle sémantique propre. Donnée brute ou multi-format: je passe par ADLS Gen2 ou Databricks avant d’exposer quoi que ce soit à Power BI.
À partir de là, je choisis le mode de connexion, puis j’ajuste la sécurité et la capacité. C’est cette séquence qui évite les refontes en cascade: source, modèle, rafraîchissement, gouvernance. Quand on respecte cet ordre, Power BI devient un vrai accélérateur du SI, pas une couche de plus posée sur des fondations fragiles.