L’essentiel à retenir sur les bases SQL
- SQL sert à manipuler des données structurées dans des tables reliées entre elles.
- Une bonne modélisation réduit les doublons, les erreurs de mise à jour et les requêtes compliquées.
- Les opérations du quotidien restent lisibles quand on maîtrise SELECT, JOIN et les transactions.
- Les index accélèrent la lecture, mais ils ont un coût sur l’écriture et le stockage.
- La sécurité dépend autant des droits, des sauvegardes et des contraintes que du langage lui-même.
- SQL reste le bon choix quand les relations entre données comptent plus que la souplesse du schéma.
Ce que couvrent vraiment les données SQL
SQL n’est pas une base de données en soi, mais le langage qui permet de piloter un système de gestion de base de données relationnelle. En pratique, cela veut dire que l’information est découpée en tables, puis organisée en lignes et en colonnes. Chaque colonne porte un type précis: texte, entier, date, booléen, décimal, et parfois des formats plus riches selon le moteur utilisé.
La force de ce modèle tient à sa rigueur. Une clé primaire identifie une ligne sans ambiguïté, une clé étrangère relie une table à une autre, et des contraintes comme NOT NULL, UNIQUE ou CHECK empêchent d’enregistrer des valeurs incohérentes. Je préfère ce cadre parce qu’il garde les données lisibles par les humains, mais aussi stables pour les applications qui les consomment.
Le mot important ici n’est pas seulement “stockage”. C’est aussi cohérence: une base relationnelle bien pensée permet de filtrer, agréger, relier et historiser les informations sans bricolage. C’est précisément ce qui la distingue d’un simple fichier ou d’un tas d’enregistrements mal reliés. Une fois cette base comprise, il devient plus simple de la structurer correctement.
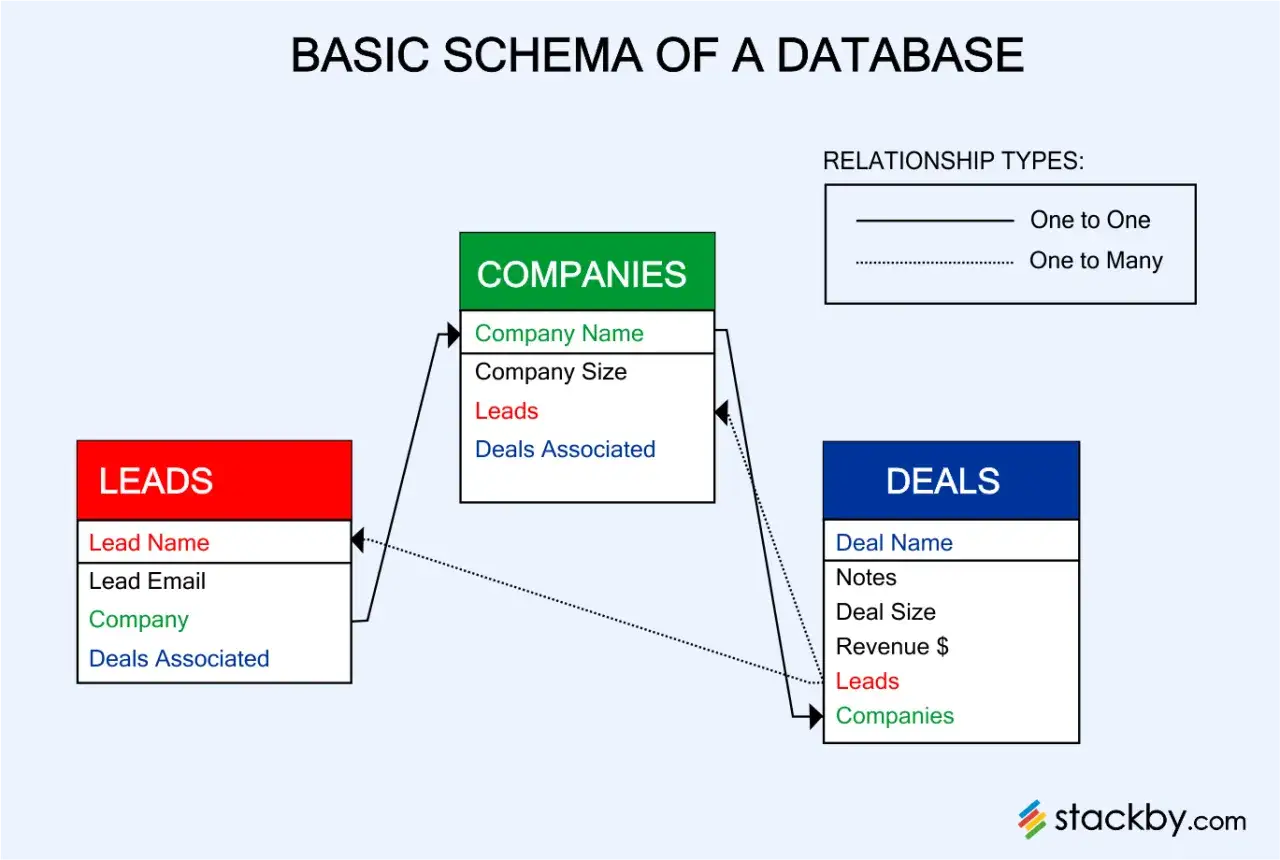
Structurer une base relationnelle pour éviter les impasses
Quand je modélise une base, je pars rarement des écrans ou des formulaires. Je pars des objets métier: client, commande, produit, paiement, facture, article, utilisateur. Ensuite, je décide ce qui doit vivre dans la même table et ce qui doit être séparé. Cette étape paraît théorique, mais elle détermine presque tout le reste: performance, maintenance, qualité des données et facilité des requêtes.
La règle la plus utile est simple: une table par entité, une relation par besoin réel. Si l’adresse d’un client est répétée dans 40 000 commandes, je crée presque toujours une structure qui évite ce doublon. Ce choix réduit le risque d’erreur lorsqu’un client change d’adresse, et il évite les mises à jour partielles qui finissent par casser la confiance dans la base.
- Clé primaire pour identifier une ligne de façon stable.
- Clé étrangère pour relier les tables sans recopier les données.
- Normalisation pour limiter les redondances et les anomalies de mise à jour.
- Table d’association pour gérer les relations plusieurs-à-plusieurs.
- Contraintes pour faire respecter les règles métier directement dans la base.
Un point que je vois souvent mal traité concerne les relations plusieurs-à-plusieurs. Au lieu d’essayer de forcer deux tables à se parler directement, je passe par une table de liaison. C’est plus propre, plus extensible et beaucoup plus lisible quand les volumes montent. Une base bien structurée n’est pas forcément plus longue à écrire; elle est surtout plus facile à exploiter ensuite, ce qui ouvre naturellement la porte aux requêtes quotidiennes.
Lire, écrire et relier les informations au quotidien
Dans la vie réelle, une base SQL sert moins à “faire du SQL” qu’à répondre vite et correctement à des besoins concrets: afficher les commandes du mois, mettre à jour un statut, compter des ventes, fusionner deux jeux de données, annuler une écriture incomplète. C’est là que le trio SELECT, INSERT, UPDATE et DELETE prend tout son sens.
Je garde toujours à l’esprit que lire une donnée et la modifier n’ont pas le même niveau de risque. Une requête de lecture mal écrite ralentit le système. Une requête de mise à jour mal pensée peut, elle, altérer la qualité de toute la base. C’est pour cela que j’accorde autant d’importance aux transactions: elles regroupent plusieurs opérations et garantissent qu’elles réussissent toutes ou qu’elles échouent toutes ensemble. Le principe ACID, pour atomicité, cohérence, isolation, durabilité, reste une bonne boussole.
SELECT c.nom, o.numero_commande, o.total
FROM clients c
JOIN commandes o ON o.client_id = c.id
WHERE o.date_commande >= '2026-01-01'
ORDER BY o.date_commande DESC;Cette requête illustre l’usage le plus fréquent: relier deux tables avec JOIN, puis filtrer les résultats utiles. C’est souvent plus puissant que d’essayer de tout stocker dans une seule table géante. Et plus la logique reste claire à ce niveau, moins on aura de mal à faire évoluer la base par la suite. La vraie difficulté arrive ensuite: faire en sorte que tout cela reste rapide.
Gagner en performance sans déformer le modèle
La performance d’une base SQL ne dépend pas seulement de la puissance du serveur. Elle dépend surtout de la qualité du schéma, du choix des index et de la façon dont les requêtes sont écrites. Je vois souvent des systèmes ralentir non pas parce qu’ils sont “trop gros”, mais parce qu’ils sont trop bavards: colonnes inutiles, jointures approximatives, filtres mal ciblés, ou index ajoutés sans méthode.
Un index accélère la recherche sur une colonne ou un ensemble de colonnes, mais il n’est jamais gratuit. Il consomme de l’espace, il demande de l’entretien, et il peut ralentir les écritures si on en abuse. Je préfère donc indexer les colonnes réellement filtrées ou jointes, puis vérifier l’effet avec le plan d’exécution avant de généraliser.
| Problème observé | Cause probable | Réflexe utile |
|---|---|---|
| Recherche lente sur une colonne filtrée | Index absent ou mal choisi | Créer un index ciblé sur la colonne réellement utilisée dans le WHERE
|
| Jointure lente entre deux grosses tables | Colonne de jointure non indexée ou cardinalité mal comprise | Indexer la colonne de relation et vérifier le plan d’exécution |
| Écritures ralenties | Trop d’index ou contraintes inutiles | Conserver seulement les index qui servent vraiment |
Deux autres habitudes changent beaucoup de choses: éviter SELECT * quand on n’a besoin que de trois colonnes, et paginer les résultats quand une interface ne peut pas tout afficher d’un coup. Sur des volumes modestes, cela semble anodin. Sur des tables de plusieurs centaines de milliers ou de millions de lignes, l’écart devient vite visible. Une base rapide n’est pas une base “magique”; c’est une base que l’on interroge proprement.
Sécuriser, sauvegarder et fiabiliser dans la durée
Une base utile aujourd’hui peut devenir un problème demain si personne ne pense aux droits, aux sauvegardes et aux règles de qualité. Je commence presque toujours par le plus simple: le moindre privilège. L’application n’a accès qu’à ce dont elle a besoin, les comptes techniques sont séparés des comptes administrateurs, et les droits de lecture sont dissociés des droits d’écriture dès que c’est possible.
Pour les sauvegardes, je regarde d’abord les objectifs de reprise. Le RPO indique combien de perte de données est acceptable. Le RTO indique combien de temps on peut tolérer l’arrêt du service. À partir de là, un schéma pratique consiste souvent à faire une sauvegarde complète quotidienne, puis des sauvegardes différentielles ou des journaux de transactions toutes les 5 à 15 minutes pour les bases critiques. Ce rythme n’est pas universel, mais il donne un ordre de grandeur réaliste quand la donnée compte vraiment.
- Tester les restaurations au moins une fois par mois, pas seulement les sauvegardes.
- Journaliser les changements sensibles pour savoir qui a modifié quoi et quand.
- Masquer ou anonymiser les données personnelles dans les environnements de recette.
- Appliquer les contraintes en base pour bloquer les valeurs absurdes avant qu’elles se propagent.
- Revoir les accès tous les trimestres pour retirer les droits devenus inutiles.
En France, je garde aussi en tête le volet RGPD dès la conception: minimisation des données, conservation limitée, accès tracé et séparation claire entre production et tests. Quand ces réflexes sont intégrés tôt, la base reste plus saine et bien plus simple à maintenir. Cette rigueur devient encore plus utile au moment de choisir entre SQL et une alternative plus souple.
SQL ou NoSQL selon le besoin
Je ne vois pas SQL et NoSQL comme deux camps opposés, mais comme deux réponses à des besoins différents. Si les relations entre entités sont fortes, si les transactions comptent et si le schéma est relativement stable, SQL est souvent le meilleur choix. Si le modèle change très vite, si les documents ont des formes très variables ou si l’application privilégie une distribution massive avec des accès très simples, une approche NoSQL peut mieux convenir.
| Besoin | SQL | NoSQL |
|---|---|---|
| Données très structurées | Excellent: schéma clair, contraintes fortes | Possible, mais souvent moins naturel |
| Relations complexes entre objets | Très bon grâce aux jointures | Plus délicat selon le modèle choisi |
| Transactions fiables | Point fort historique | Variable selon la technologie |
| Schéma très flexible | Possible, mais demande une discipline de migration | Souvent plus confortable |
| Analyse et reporting | Très adapté | Peut nécessiter une couche supplémentaire |
Dans la plupart des projets métier, je commence par SQL parce qu’il donne un cadre robuste et lisible. Je bascule vers autre chose seulement quand la contrainte de souplesse ou d’échelle est réellement dominante, pas par effet de mode. Autrement dit, le bon choix n’est pas celui qui semble le plus moderne, mais celui qui résout le mieux le problème réel. Et quand ce choix est posé, il reste à garder la base exploitable sur la durée.
Les réflexes que je garde pour une base durable
- Je pars des questions métier avant de dessiner les tables.
- Je garde un schéma simple tant que la complexité n’est pas justifiée.
- Je documente les clés, les conventions de nommage et les champs obligatoires.
- Je mesure avant d’optimiser, puis je valide l’effet sur des requêtes réelles.
- Je teste les restaurations autant que les sauvegardes.
Au fond, une bonne base SQL n’est pas celle qui contient le plus de tables ou les requêtes les plus longues. C’est celle qui reste prévisible, propre, protégée et facile à faire évoluer quand l’activité change. Si je devais résumer l’approche en une phrase, je dirais ceci: des données bien modélisées valent toujours mieux qu’un stockage rapide mais fragile.