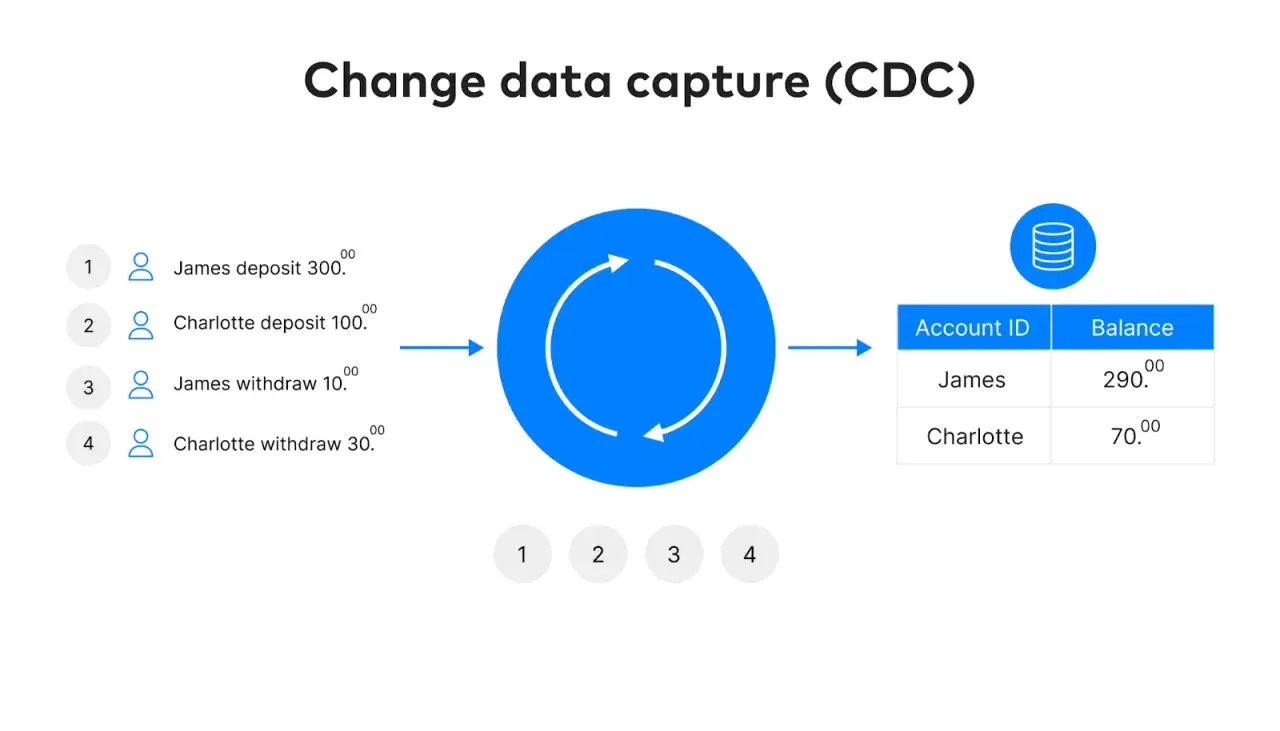
Le CDC dans SQL Server sert à suivre les insertions, mises à jour et suppressions sans relire toute la base à chaque exécution. Je l’utilise surtout quand un SI de données doit alimenter un entrepôt, synchroniser une cible ou conserver une trace exploitable des modifications. Dans cet article, je vais aller droit au but : comment il fonctionne, comment l’activer, comment lire les changements et surtout où se trouvent ses limites réelles.
L’essentiel à retenir avant de le brancher à votre SI
- Le CDC lit le journal des transactions, puis écrit les modifications dans des tables de changement dédiées.
- On active d’abord la base, puis les tables ; au niveau base, il faut un compte sysadmin, et au niveau table un db_owner ou un sysadmin.
- Par défaut, SQL Server conserve 3 jours de données de changement et un nettoyage automatique évite que les tables grossissent sans limite.
- Pour consommer les données, on passe par les fonctions de lecture du type all changes ou net changes, selon le niveau de détail voulu.
- Si vous n’avez besoin que de savoir qu’une ligne a changé, Change Tracking peut suffire et coûter moins cher à exploiter.
- Les colonnes calculées sont renvoyées à NULL, et certaines opérations DDL ou d’indexation en ligne restent incompatibles avec CDC.
Comment le CDC lit le journal sans copier toute la base
Le point clé, c’est que CDC ne surveille pas les tables comme le ferait un trigger. Il s’appuie sur le journal des transactions, donc sur ce que SQL Server enregistre déjà quand une ligne est insérée, mise à jour ou supprimée. Ensuite, le moteur copie ces changements dans une capture instance, c’est-à-dire un ensemble composé d’une table de changement et de fonctions de lecture associées.
Je résume souvent la mécanique ainsi : la base source continue de travailler normalement, et CDC fabrique en arrière-plan une vue exploitable des deltas. C’est précisément ce qui le rend intéressant pour un flux incrémental, mais aussi ce qui impose de respecter sa fenêtre de lecture et sa logique de rétention.
| Métadonnée | Rôle | Pourquoi je m’y fie |
|---|---|---|
__$start_lsn |
LSN de commit associé au changement | Il ordonne les changements dans le temps |
__$seqval |
Ordre interne des lignes dans une même transaction | Il évite les ambiguïtés quand plusieurs changements sont groupés |
__$operation |
Type d’opération | Il indique si l’on traite un insert, un delete ou un update |
__$update_mask |
Masque des colonnes modifiées | Il permet de voir ce qui a réellement changé |
Sur un UPDATE, CDC peut produire deux lignes, une avant et une après modification, ce qui est très utile si l’on veut rejouer fidèlement l’historique dans un autre système. C’est ce niveau de détail qui distingue CDC d’un simple drapeau de modification, et c’est aussi pour cela qu’il s’insère bien dans les architectures d’intégration de données.
Les cas d’usage où il apporte vraiment de la valeur
Dans un SI, je le recommande surtout quand la cible n’est pas une copie parfaite de la source. Un entrepôt de données, un datamart, une base analytique ou un moteur de recherche interne peuvent consommer les deltas pour reconstruire leur propre modèle, sans faire repartir tout le volume à zéro à chaque cycle. C’est là que CDC devient intéressant : il fournit un flux de changements structuré, pas une simple réplication binaire de la base.
- Chargement incrémental d’un entrepôt de données, quand le volume rend le full refresh trop coûteux.
- Synchronisation de SI entre une base opérationnelle et une cible métier qui n’a pas la même structure.
- Historisation de certaines évolutions pour garder une trace exploitable des changements.
- Reprise d’activité ou reconstruction partielle, quand il faut rejouer une plage de modifications.
Je m’en sers rarement pour un besoin de copie stricte temps réel, parce que ce n’est pas son métier. En revanche, pour de l’incrémental fiable, il est très à sa place. Si le besoin est plus léger, le bon outil n’est pas forcément CDC, et c’est là que la comparaison suivante devient utile.
CDC ou Change Tracking selon ce que votre SI doit réellement savoir
Je ne confonds pas CDC avec Change Tracking. Les deux suivent les modifications, mais ils ne répondent pas au même niveau d’exigence. CDC enregistre l’historique détaillé des données modifiées ; Change Tracking dit surtout qu’une ligne a changé, sans garder la même richesse d’information.
| Critère | CDC | Change Tracking |
|---|---|---|
| Niveau de détail | Valeurs avant/après, métadonnées de changement | Indique qu’une ligne a changé, sans historique complet |
| Historique | Oui | Non |
| Latence | Asynchrone, dépend du traitement du journal | Synchronisé avec les opérations DML |
| Coût fonctionnel | Plus riche, donc plus exigeant | Plus léger |
| Usage typique | ETL, historisation, rejouage de changements | Synchronisation simple d’état |
Je choisis CDC quand je dois reconstruire l’histoire des données ou transmettre des changements précis vers une autre représentation métier. Je choisis Change Tracking quand je veux seulement savoir quelles lignes ont bougé depuis le dernier passage. Et, point pratique important, les deux peuvent coexister sur la même base. Une fois ce choix posé, il faut l’installer proprement, sans casser le log ni les jobs.
L’activation propre, de la base à la table
La règle qui évite la plupart des échecs est simple : on active d’abord la base, puis les tables. La base doit être ouverte par un compte sysadmin, et la table par un compte sysadmin ou db_owner. Je vérifie aussi qu’aucun schéma ni utilisateur nommé cdc n’existe déjà, parce que ce nom est réservé au mécanisme lui-même.
- Vérifier l’édition SQL Server et les droits du compte utilisé.
- Contrôler qu’aucun schéma ou utilisateur
cdcn’existe déjà dans la base. - Activer CDC au niveau base avec
sys.sp_cdc_enable_db. - Activer la table source avec
sys.sp_cdc_enable_table. - Valider l’état avec les colonnes
is_cdc_enabledetis_tracked_by_cdc.
USE MaBase;
GO
EXEC sys.sp_cdc_enable_db;
GOEXEC sys.sp_cdc_enable_table
@source_schema = N'dbo',
@source_name = N'Commandes',
@role_name = N'cdc_reader',
@supports_net_changes = 1;
GOSi vous activez @supports_net_changes = 1, la table source doit avoir une clé primaire ou un index unique. C’est un détail que beaucoup ratent au début, alors qu’il conditionne la fonction de lecture la plus pratique pour les synchronisations incrémentales. Ensuite, tout se joue dans la manière de lire les changements, car une mauvaise fenêtre LSN donne vite de faux résultats.
Lire les changements sans se tromper de fenêtre LSN
La lecture se fait par tranche de LSN, pour Log Sequence Number. En pratique, je pense toujours en fenêtre de consommation : une borne basse, une borne haute, et la certitude que la plage demandée reste couverte par les données encore conservées. Si la fenêtre est trop ancienne, le nettoyage automatique peut avoir supprimé les lignes ; si elle est trop récente, la capture n’a pas encore rattrapé le journal.
| Fonction | Ce qu’elle renvoie | Quand je l’utilise |
|---|---|---|
cdc.fn_cdc_get_all_changes_... |
Tous les changements de la plage, avec parfois deux lignes pour un update | Rejeu complet, audit, alimentation détaillée |
cdc.fn_cdc_get_net_changes_... |
Une seule ligne nette par ligne source | Synchronisation incrémentale simple |
sys.fn_cdc_get_min_lsn / sys.fn_cdc_get_max_lsn
|
Les bornes disponibles de la fenêtre | Éviter de demander une plage hors validité |
DECLARE @from_lsn binary(10) = sys.fn_cdc_get_min_lsn('dbo_Commandes');
DECLARE @to_lsn binary(10) = sys.fn_cdc_get_max_lsn();
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_Commandes(@from_lsn, @to_lsn, 'all');Dans la logique “all changes”, un update peut apparaître sous forme d’une ligne avant modification et d’une ligne après modification. Dans la logique “net changes”, on ne garde que l’état final de la ligne sur la plage choisie. C’est souvent ce deuxième mode qui simplifie la vie des équipes SI, à condition d’avoir la clé ou l’index requis. Mais une bonne extraction ne suffit pas si l’exploitation quotidienne est mal cadrée.
Les limites qui comptent vraiment en production
C’est ici que beaucoup de projets se compliquent, pas au moment de l’activation mais quelques semaines plus tard. Par défaut, CDC conserve 3 jours de données ; sur SQL Server et Azure SQL Managed Instance, le nettoyage est assuré par un job de cleanup, tandis que le capture job démarre en continu avec des réglages par défaut de 1000 transactions par cycle et 5 secondes d’attente entre cycles. Si les consommateurs lisent trop lentement, la fenêtre se resserre et vous pouvez perdre des changements.
| Point de vigilance | Impact réel | Ce que je fais |
|---|---|---|
| Rétention par défaut de 3 jours | Les anciennes lignes de changement disparaissent automatiquement | Aligner la rétention sur le délai maximum de consommation |
| SQL Server Agent doit tourner | Sans lui, la capture et le nettoyage ne suivent plus | Le surveiller comme un service critique |
| Opérations d’index en ligne | Elles ne sont pas prises en charge quand CDC est activé | Planifier les maintenances avec prudence |
| Colonnes calculées | Les valeurs remontent à NULL
|
Ne pas baser une logique métier sur ces champs dans CDC |
| Changements de type ou de taille | Ils peuvent casser le scan ou produire des erreurs de conversion | Tester les DDL avant déploiement et revalider les capture instances |
Schéma ou utilisateur cdc déjà présent |
L’activation échoue | Réserver ce nom et éviter toute création manuelle |
| ADR et CDC | La coexistence n’est pas supportée sur SQL Server 2019 ; elle l’est à partir de SQL Server 2022 CU18 | Vérifier la version avant de compter sur les deux mécanismes |
| Restauration sur un autre serveur | CDC est désactivé par défaut sauf si l’on utilise KEEP_CDC
|
Documenter la stratégie de restore |
En cas d’anomalie, je regarde en premier sys.dm_cdc_errors avant de toucher aux objets système. Et je garde toujours en tête que CDC n’aime pas les modifications manuelles de ses métadonnées, ni les DDL improvisés sur des tables déjà suivies. Avec ces garde-fous, on peut l’intégrer sereinement dans un SI de données.
Les derniers réglages qui évitent les surprises dans un SI de données
En 2026, CDC reste une très bonne option quand il faut un flux fiable, historisé et peu intrusif. Pour que cela tienne dans la durée, je verrouille trois choses : la fenêtre de rétention, la capacité des consommateurs à suivre la cadence, et la discipline sur les changements de schéma. Si ces trois points sont clairs, le reste devient beaucoup plus simple à exploiter.
- Je documente la borne basse et la borne haute de chaque extraction LSN.
- Je teste les DDL avant de toucher une table déjà suivie par CDC.
- Je surveille le journal des transactions et la latence de capture comme des indicateurs d’exploitation.
- Je choisis Change Tracking si le besoin se limite à un delta léger, sans historique détaillé.
Mon avis est assez net : CDC n’est pas l’outil le plus simple, mais c’est l’un des plus solides dès qu’un SI doit rejouer précisément les changements d’une base SQL Server. Si vous avez besoin d’historique, de détail et d’un vrai flux incrémental, il mérite sa place. Si vous n’avez besoin que d’un signal de modification, je descendrais d’un cran en complexité et je regarderais Change Tracking avant tout le reste.