L’essentiel à retenir avant de l’adopter
- Une table Delta est un ensemble de fichiers de données accompagné d’un journal transactionnel qui enregistre chaque changement.
- Le vrai gain est l’ACID en environnement de data lake: pas de lecture d’un état partiel, pas d’écriture silencieusement corrompue.
- La table devient utile dès qu’il y a du multi-écriture, du streaming, du CDC, de l’upsert ou des besoins d’audit.
- Elle unifie mieux les traitements batch et temps réel, ce qui simplifie souvent les pipelines.
- Elle demande malgré tout de la discipline: taille des fichiers, compaction, politique de rétention et gouvernance restent essentiels.
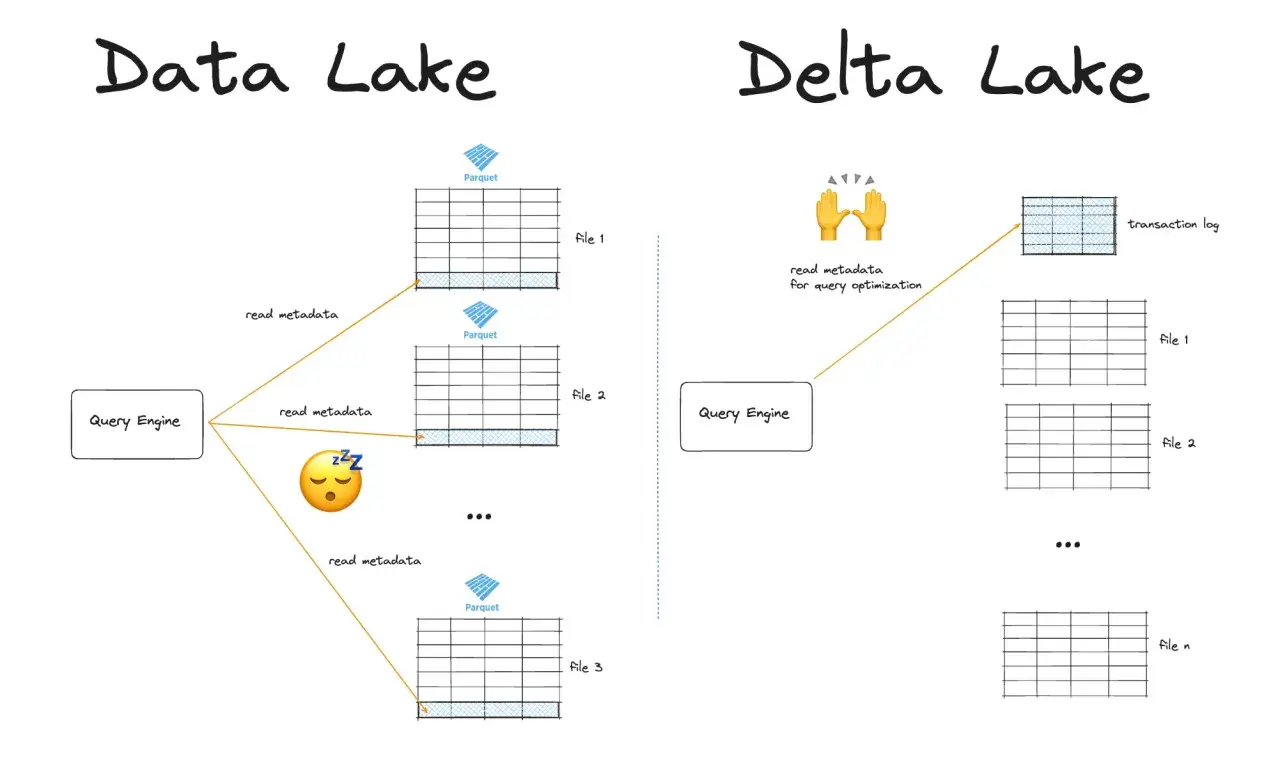
Ce que change un stockage transactionnel dans un data lake
Dans un lac de données “brut”, on manipule souvent des fichiers Parquet comme une simple couche de stockage. C’est souple, mais pas suffisant dès que plusieurs jobs écrivent en même temps, qu’un pipeline doit corriger une ligne déjà chargée ou qu’un utilisateur attend des données cohérentes pendant l’exécution d’un traitement. Sans couche transactionnelle, on finit vite avec des lectures partielles, des doublons, des remplacements incomplets ou des schémas qui dérivent sans contrôle.
Une table Delta ajoute une logique de base beaucoup plus robuste: les fichiers restent sur un stockage objet classique, mais chaque modification est enregistrée dans un journal qui sert de source de vérité. Autrement dit, on ne lit pas “les fichiers au hasard”, on lit un état validé de la table. C’est ce qui permet d’obtenir l’atomicité, la cohérence, l’isolation et la durabilité, les quatre propriétés de l’ACID.
| Approche | Ce que vous obtenez | Limite principale |
|---|---|---|
| Data lake classique | Stockage simple, peu coûteux, très flexible | Pas de garantie native sur les écritures concurrentes ni sur l’historique |
| Table Delta | Transactions, historique, lectures cohérentes, upserts | Besoin d’un peu plus d’exploitation et de discipline de maintenance |
| Entrepôt analytique traditionnel | Fort niveau de gouvernance et requêtes stables | Moins souple pour le brut, le streaming ou certains scénarios hybrides |
Je résume souvent la différence ainsi: le lac de données stocke, la table transactionnelle organise et sécurise. Et pour comprendre pourquoi cela fonctionne réellement, il faut regarder le mécanisme interne. C’est ce que je détaille maintenant.
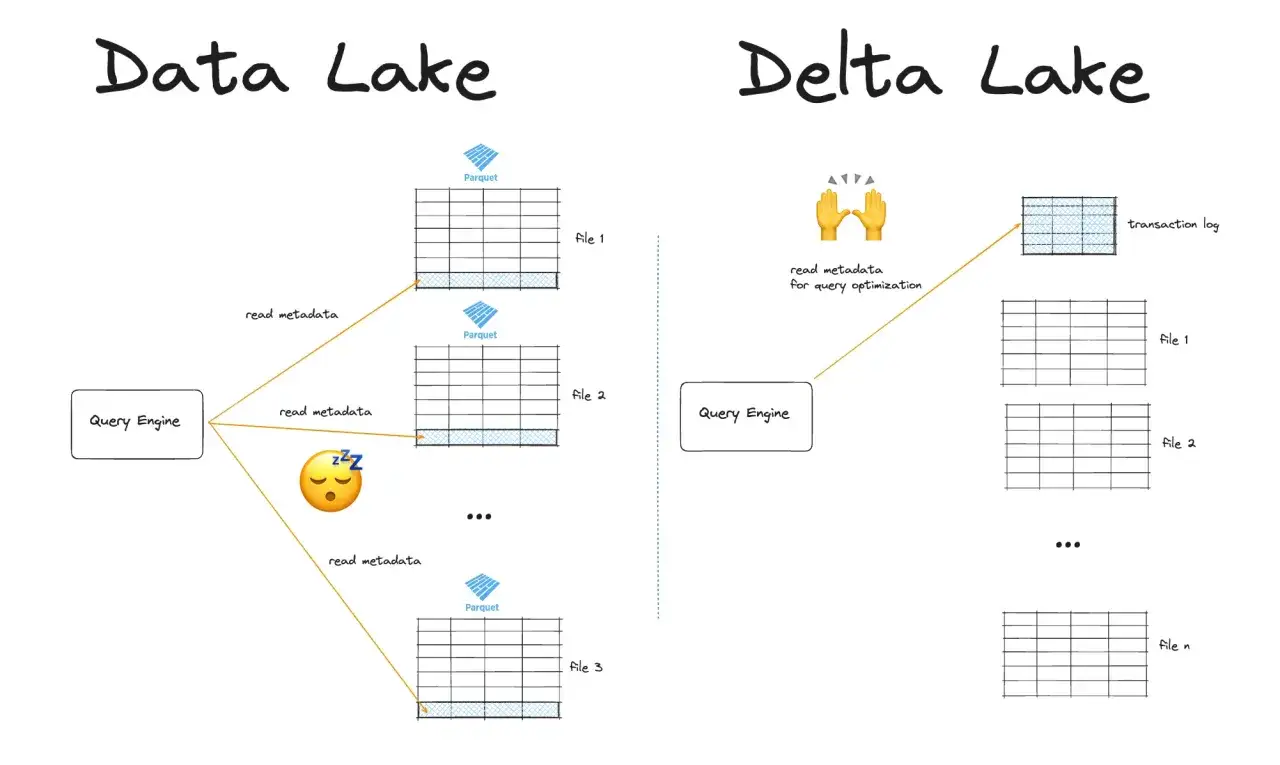
Comment la couche Delta sécurise les écritures
Le cœur du système, c’est le journal transactionnel. Chaque opération importante ajoute une entrée qui décrit ce qui a été créé, modifié ou supprimé. On ne réécrit pas toute la table à chaque fois; on décrit les changements, puis le moteur construit l’état cohérent de la table à partir de ce journal et des fichiers de données. Ce principe change beaucoup de choses en pratique, surtout quand les volumes montent.
Le journal comme source de vérité
Le journal enregistre les opérations sous forme d’ajouts, de suppressions et de métadonnées. Ce n’est pas un détail technique: c’est ce qui évite qu’un traitement interrompu laisse la table dans un état ambigu. Si le commit n’est pas validé, il n’existe pas pour les lecteurs. Cette logique “tout ou rien” est précisément ce que beaucoup d’équipes recherchent lorsqu’elles passent d’un simple data lake à une architecture plus fiable.
Des lectures cohérentes pour les utilisateurs et les jobs
Le moteur lit une snapshot, c’est-à-dire une image stable de la table à un instant donné. Résultat: un dashboard, un notebook ou un pipeline ne “voit” pas la table changer sous ses pieds pendant son exécution. C’est particulièrement important pour les traitements lourds, les recalculs analytiques et les chaînes de transformation où la reproductibilité compte autant que la performance.
Lire aussi : ECM - Guide complet pour choisir votre plateforme de contenu
Une concurrence gérée de façon optimiste
La concurrence est gérée de manière optimiste, ce qui veut dire que plusieurs écritures peuvent être tentées en parallèle, mais qu’un conflit est détecté si deux opérations se battent sur la même zone logique de la table. On ne bloque pas tout par défaut; on vérifie au moment du commit. Cette approche évite beaucoup de contention inutile, à condition que les pipelines soient bien conçus.
Il y a toutefois une condition qu’on oublie trop souvent: la garantie transactionnelle dépend aussi du stockage sous-jacent. Le système de fichiers ou l’objet stocké doit permettre une visibilité atomique, une exclusivité correcte à l’écriture et une liste cohérente des fichiers. Sinon, il faut une couche d’adaptation adaptée à l’environnement. C’est une réalité d’architecture, pas un détail de configuration, et elle explique pourquoi la robustesse ne vient pas seulement du format, mais de l’ensemble de la chaîne. À partir de là, les bénéfices métier deviennent beaucoup plus concrets.
Les gains concrets pour les équipes data et SI
Je trouve que le sujet devient vraiment utile quand on quitte la théorie pour les usages quotidiens. Les équipes ne cherchent pas seulement “un format moderne”; elles veulent réduire les incidents, simplifier les flux et garder une trace fiable des changements. C’est exactement là que le format Delta apporte de la valeur.
| Cas d’usage | Pourquoi c’est pertinent | Bénéfice concret |
|---|---|---|
| Ingestion incrémentale | On charge seulement ce qui change | Moins de coûts, moins de réécritures, pipelines plus rapides |
| CDC et upserts | Les lignes évoluent au lieu d’être réimportées en bloc | On évite les rechargements complets et les doublons |
| BI et reporting | Les lecteurs voient un état stable de la table | Les indicateurs restent reproductibles et auditables |
| Streaming et batch | Une même table sert de source et de destination | Moins de duplication d’architecture et moins de zones d’ombre |
| Préparation ML | Les versions passées restent accessibles | Expériences reproductibles et meilleure traçabilité des features |
Il y a un autre gain que je vois souvent sous-estimé: la qualité de données. La validation de schéma à l’écriture et les contraintes évitent d’injecter silencieusement des lignes mal formées. Ce n’est pas magique, mais cela réduit les erreurs “fantômes” qui finissent par polluer un modèle, un reporting ou une consolidation financière. Quand les transformations deviennent fiables, la discussion se déplace vers l’architecture elle-même: où Delta est-il vraiment le bon choix, et quand faut-il rester plus sobre?
Quand je le recommande et quand je reste prudent
Je recommande une table transactionnelle dès qu’un même jeu de données est lu et modifié par plusieurs traitements, ou quand il faut faire cohabiter ingestion streaming, corrections tardives et analytique. C’est aussi une bonne réponse pour les SI qui ont besoin d’un historique exploitable, d’une logique de reprise propre et d’une gouvernance plus sérieuse sur les écritures.
En revanche, je reste prudent dans trois cas fréquents. D’abord, si le besoin est purement append-only et très simple, le surcoût opérationnel peut ne pas se justifier. Ensuite, si l’environnement multiplie les petits fichiers sans stratégie de compaction, les performances se dégradent vite. Enfin, si votre priorité absolue est l’interopérabilité entre plusieurs moteurs de calcul, il faut comparer le format Delta avec d’autres formats ouverts selon la stack en place, et ne pas choisir par réflexe.
- Bon candidat si vous avez des upserts, des corrections, du CDC ou des traitements parallèles.
- Bon candidat si vous devez rejouer l’historique ou auditer précisément les changements.
- À surveiller si vos fichiers sont trop petits, trop nombreux ou trop fragmentés.
- À surveiller si l’équipe n’a pas de politique claire de rétention, de maintenance et de gouvernance.
- À comparer si votre SI repose sur plusieurs moteurs et que l’indépendance d’écosystème prime sur tout le reste.
Autrement dit, ce n’est pas “oui ou non” par principe. C’est une réponse très solide quand le problème principal est la fiabilité des écritures et la cohérence des lectures. Si le problème est ailleurs, par exemple dans l’orchestration, la modélisation ou la qualité des sources, le format seul ne réglera rien. Une fois ce tri fait, on peut construire quelque chose de propre et durable. La question suivante est donc très opérationnelle: comment l’implémenter sans créer une dette cachée?
Ce que je mettrais en place dans un SI data
Quand je conçois une chaîne autour de tables Delta, je pars presque toujours d’une architecture en couches. Cela évite de mélanger le brut, le nettoyé et le prêt à consommer. Cette séparation n’est pas décorative; elle réduit les risques de réécriture sauvage, clarifie la responsabilité de chaque étape et simplifie l’exploitation.
- Bronze pour l’ingestion brute, sans transformation agressive. Je conserve les données telles qu’elles arrivent pour garder une trace exploitable.
-
Silver pour le nettoyage, la déduplication et les corrections métier. C’est souvent là que les
mergeprennent tout leur sens. - Gold pour les tables de consommation destinées au BI, aux API ou aux usages métiers sensibles.
- Partitionnement raisonné pour éviter d’exploser le nombre de fichiers. Je partitionne seulement sur des dimensions réellement utiles à la lecture.
- Compaction et maintenance pour regrouper les petits fichiers et contrôler la rétention de l’historique.
- Surveillance des conflits, des dérives de schéma et du volume de fichiers, parce que ce sont les premiers signaux d’un pipeline qui se fragilise.
Je conseille aussi d’être strict sur deux points: les politiques de rétention et la gestion des mises à jour de schéma. Le format sait gérer l’évolution, mais une évolution non gouvernée finit toujours par coûter cher quelque part. Une équipe qui documente ses tables, ses responsabilités et ses règles de conservation gagne du temps à moyen terme, même si cela demande un peu plus de rigueur au départ. C’est aussi ce qui distingue une adoption sérieuse d’un simple test technique.
Les points à verrouiller avant de l’exploiter en continu
Avant de passer en production, je vérifie toujours quatre choses: la qualité du stockage sous-jacent, la stratégie de maintenance, la discipline sur les schémas et la capacité de l’équipe à diagnostiquer les conflits d’écriture. Sans ces garde-fous, on bénéficie du format mais on récupère aussi ses zones de friction, surtout à grande échelle.
Mon conseil le plus pragmatique est simple: commencez par un cas où la douleur est nette, par exemple un flux CDC, un reporting sensible ou une chaîne batch plus streaming, puis étendez progressivement. Les tables Delta donnent leur meilleur rendement quand elles résolvent un vrai problème de fiabilité, pas quand elles servent seulement à moderniser le vocabulaire de l’architecture. Si je devais résumer la logique en une phrase, je dirais qu’elles rendent le data lake enfin exploitable comme un système sérieux, sans lui faire perdre sa flexibilité.