Voici l’essentiel avant d’aller plus loin
- Un SI relie les données, les applications, les processus et les personnes, pas seulement les logiciels.
- La valeur vient moins de la quantité d’outils que de la qualité des données et des règles qui les encadrent.
- Une architecture simple, documentée et évolutive tient mieux qu’une pile technique trop ambitieuse.
- La sécurité doit être pensée dès le départ, notamment pour les accès, les journaux et les sauvegardes.
- Les bons indicateurs sont concrets : fraîcheur des données, doublons, délais d’accès, incidents et restauration.
Ce qu’est vraiment un système d’information
Je distingue toujours le SI d’une simple infrastructure technique. L’infrastructure fournit le terrain de jeu ; le système organise la manière dont l’entreprise collecte, valide, partage et utilise l’information. Autrement dit, ce n’est pas un logiciel unique ni une base de données isolée, mais un ensemble cohérent qui doit servir un usage métier précis.
Dans une équipe éditoriale, par exemple, un CMS, un CRM, un espace documentaire, un outil de planification et une facturation peuvent former un SI à condition d’être reliés par des règles claires. Dans une structure musicale, on retrouvera souvent en plus la gestion des droits, des catalogues et des métadonnées. Le point commun reste le même : la donnée n’a de valeur que si elle circule au bon endroit, au bon moment, et avec le bon niveau de fiabilité.
- La donnée : ce que l’organisation collecte, corrige, conserve et exploite.
- Les applications : CMS, CRM, ERP, outils métiers, reporting, messagerie, GED.
- Les processus : validation, publication, archivage, support, facturation, contrôle.
- Les personnes : métiers, IT, direction, prestataires et utilisateurs finaux.
- Les règles : droits d’accès, traçabilité, rétention, conformité, supervision.
Une fois cette base posée, la vraie question devient celle des briques qui le font vivre au quotidien.
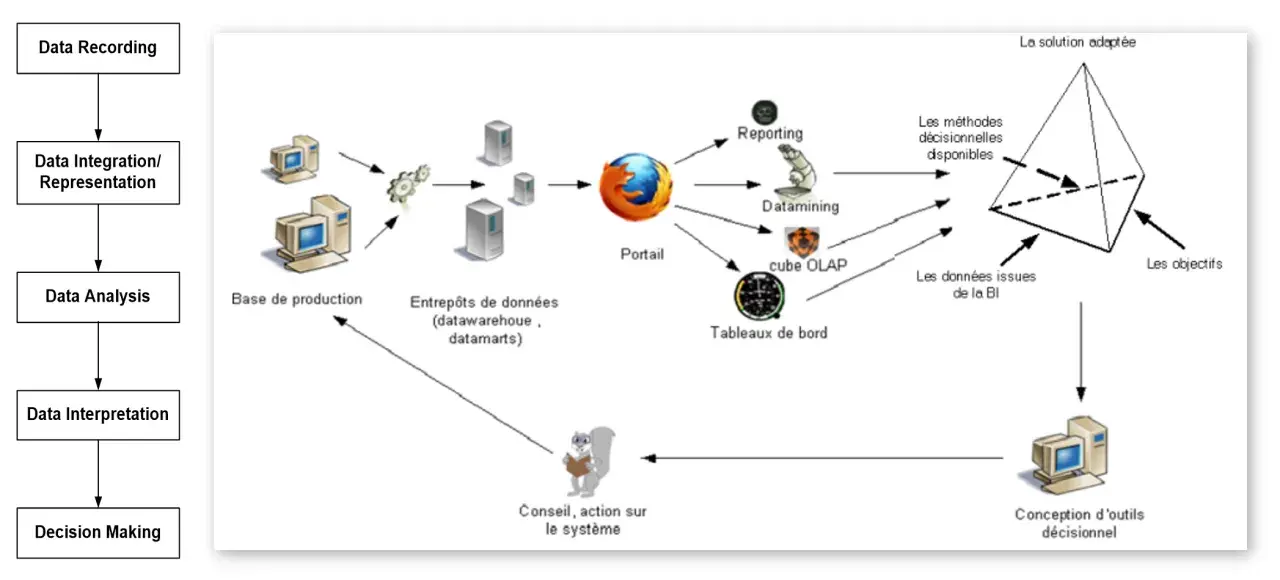
Les briques qui le composent au quotidien
Quand un SI fonctionne bien, on ne le remarque presque pas. Quand il fonctionne mal, en revanche, tout ralentit : ressaisie, doublons, erreurs de version, documents introuvables, droits trop larges ou flux cassés entre deux outils. C’est souvent là que l’on comprend que le problème n’est pas le manque d’outils, mais l’absence d’alignement entre eux.
| Brique | Rôle | Ce qui se passe si elle est mal gérée |
|---|---|---|
| Données de référence | Elles évitent les doublons sur les clients, produits, contenus ou partenaires. | Les équipes ne parlent plus de la même chose et les rapports deviennent incohérents. |
| Applications métier | Elles orchestrent les tâches du quotidien et portent les usages concrets. | On ressaisit les informations à la main et les erreurs se multiplient. |
| Infrastructure | Serveurs, cloud, réseau et postes de travail soutiennent l’ensemble. | Le SI devient lent, instable ou indisponible au mauvais moment. |
| Processus | Ils définissent qui valide, qui modifie et qui publie. | Les outils existent, mais les équipes contournent sans cesse les règles. |
| Sécurité et supervision | Elles protègent l’accès, suivent les incidents et rendent les dérives visibles. | On découvre le problème trop tard, souvent après une perte de données. |
Ce schéma est utile parce qu’il oblige à penser le SI comme une chaîne, pas comme un catalogue d’outils. Dès qu’une brique est fragile, c’est tout le flux d’information qui se dégrade. C’est justement pour cela que la gestion des données mérite un traitement à part.
La donnée n’a de valeur que si son cycle est maîtrisé
La donnée est souvent le vrai point de blocage. Un SI peut être moderne et rester inefficace si l’on ne sait pas quelle source fait foi, qui corrige une erreur, ni quand une information devient obsolète. Je préfère donc raisonner en cycle de vie plutôt qu’en simple stockage.
Le cycle de vie des données
Je le découpe en six gestes simples : collecter, qualifier, stocker, exposer, archiver et supprimer. À chaque étape, il faut savoir qui agit, avec quel contrôle, et selon quelle règle. C’est ce qui permet d’éviter les archives inutiles, les doublons et les jeux de données impossibles à auditer.
- Collecter sans multiplier les champs inutiles ni les formulaires trop longs.
- Qualifier en vérifiant l’exactitude, la complétude et la cohérence.
- Stocker dans un emplacement identifié, avec un niveau d’accès adapté.
- Exposer la donnée aux bons outils, via des API ou des exports contrôlés.
- Archiver ce qui doit être conservé, mais n’a plus d’usage opérationnel immédiat.
- Supprimer ce qui n’a plus de raison d’être conservé, pour limiter les risques et le bruit.
La modélisation évite les bricolages
Quand je veux rendre un projet solide, je commence presque toujours par la modélisation. En pratique, cela veut dire clarifier les objets métier avant de toucher aux tables ou aux écrans. Un bon modèle évite qu’un même mot désigne des réalités différentes selon le CRM, le CMS ou l’outil de facturation.
Je vois cette logique en trois niveaux : le niveau conceptuel, qui décrit le vocabulaire métier ; le niveau logique, qui précise les relations entre les entités ; et le niveau physique, qui se traduit dans la base de données, les index et les contraintes techniques. Ce passage progressif évite le grand classique du projet mal cadré : un outil qui marche, mais que personne n’ose faire évoluer.
Lire aussi : CDC Data - Maîtriser la capture de changements pour votre SI
Les rôles qui évitent les zones grises
Une petite équipe pense souvent qu’elle peut se passer de gouvernance formelle. En réalité, plus l’organisation est légère, plus il faut être clair. J’aime au minimum définir un propriétaire par domaine de donnée, une personne qui arbitre les corrections, et un responsable technique qui garantit la mise en œuvre. Sans cela, chaque anomalie devient un sujet collectif sans décision nette.
Quand ces rôles existent, le choix de l’architecture devient beaucoup plus lisible. Et c’est précisément là que beaucoup de projets gagnent ou perdent en souplesse.
Choisir l’architecture adaptée à la taille et aux usages
Je recommande rarement une architecture “à la mode” si elle complique la vie des équipes. Le bon choix dépend du volume de données, du nombre d’outils, du niveau de sensibilité des informations et du rythme de changement attendu. Une petite structure n’a pas les mêmes besoins qu’une organisation qui gère plusieurs métiers, plusieurs sites ou plusieurs canaux numériques.
| Architecture | Quand elle convient | Atouts | Limites |
|---|---|---|---|
| Centralisée et peu découpée | Petit périmètre, équipe réduite, flux simples | Moins de complexité, démarrage rapide, coût maîtrisé | Évolue difficilement et devient vite rigide |
| Modulaire avec API | Plusieurs outils doivent échanger proprement | Bonne évolutivité, meilleure séparation des fonctions | Demande de la discipline sur les interfaces et la documentation |
| Cloud | Besoin d’élasticité, d’accès distant ou de déploiements rapides | Souplesse, services managés, moins d’infrastructure à maintenir | Attention aux coûts récurrents et à la dépendance au fournisseur |
| Hybride | Données sensibles, héritage existant, transition progressive | Compromis entre contrôle et flexibilité | Plus difficile à administrer si le cadrage est flou |
Dans la pratique, je vois souvent un cadrage sérieux prendre 2 à 6 semaines, une migration progressive s’étaler sur 3 à 9 mois, et une refonte plus large dépasser l’année lorsqu’elle touche plusieurs métiers. Ce n’est pas une règle universelle, mais c’est un ordre de grandeur utile pour éviter les promesses irréalistes.
Une fois l’architecture choisie, il reste un sujet que beaucoup traitent trop tard : la sécurité et la conformité.
Sécurité et conformité ne sont pas des options
Un SI de données qui n’est pas sécurisé finit toujours par coûter plus cher que prévu, soit en incident, soit en perte de confiance. Je préfère une approche pragmatique : moins de privilèges, plus de traces, des sauvegardes testées et des droits revus régulièrement. C’est moins spectaculaire qu’un grand chantier de refonte, mais bien plus rentable.- Authentification multi-facteur pour les accès sensibles et les comptes administrateurs.
- Droits minimaux : chacun voit seulement ce dont il a besoin pour travailler.
- Journalisation des accès et des actions critiques pour comprendre un incident après coup.
- Chiffrement des données sensibles et des supports nomades.
- Sauvegardes testées avec un vrai test de restauration, pas seulement une copie automatique.
- Revue des accès à rythme fixe, idéalement trimestriel pour les environnements les plus exposés.
La CNIL insiste notamment sur la journalisation des flux de données qui transitent sur le système et sur la capacité à analyser un incident a posteriori. Ce point est souvent sous-estimé, alors qu’il change tout quand il faut comprendre ce qui s’est passé et quand cela a commencé.
Service-Public rappelle aussi que le travail hors des locaux ajoute des risques spécifiques, notamment avec les ordinateurs portables, les clés USB, les smartphones et les réseaux publics. Dans ce contexte, je considère le VPN avec authentification forte comme un réflexe de base, pas comme une option avancée.
Une fois ces garde-fous posés, il reste à piloter le système avec des indicateurs simples et lisibles.
Les indicateurs qui disent si votre SI reste maîtrisé
Je surveille rarement une liste interminable de métriques. En revanche, quelques signaux faibles suffisent à dire si le SI devient trop lourd, trop flou ou trop risqué. Si ces indicateurs se dégradent, ce n’est généralement pas un détail technique : c’est le signe que la donnée, les outils ou les responsabilités ne sont plus bien alignés.
- Le temps moyen pour retrouver une information critique.
- Le taux de doublons dans les référentiels clients, produits ou contenus.
- Le nombre de traitements sans propriétaire clairement identifié.
- Le délai de restauration après incident ou panne.
- La part d’applications documentées, avec flux et responsabilités à jour.
- La fréquence de mise à jour des données, surtout dans les usages qui demandent de la fraîcheur.
Si je devais donner une méthode de départ très concrète, je commencerais par cartographier les trois flux de données les plus critiques, nommer un responsable par domaine, vérifier les sauvegardes, puis automatiser un seul processus manuel qui coûte du temps tous les jours. C’est souvent là que l’on passe d’un SI subi à un SI réellement utile.