
Le masquage des données sert à rendre des informations sensibles exploitables sans exposer les valeurs réelles. Le data masking devient intéressant quand la donnée doit circuler sans perdre sa structure ni sa cohérence. En pratique, c’est souvent ce qui permet de garder des jeux de test crédibles, d’alimenter des environnements de préproduction et de partager des données avec moins de risque.
Les points qui comptent vraiment avant de choisir une approche
- Le masquage remplace des valeurs sensibles par des équivalents crédibles, mais il ne remplace pas une vraie politique d’accès.
- Le masquage statique convient surtout aux copies de test et d’analyse, tandis que le masquage dynamique agit à la lecture.
- Le sujet se distingue clairement de l’anonymisation, de la pseudonymisation et du chiffrement.
- Une bonne mise en place doit préserver la cohérence entre les tables et les règles métier.
- Les erreurs les plus coûteuses viennent souvent des exports, des logs, des backups et des droits trop larges.
Ce que recouvre réellement le masquage des données
Je préfère partir d’une définition simple: on prend une donnée sensible et on la remplace par une valeur fictive, mais suffisamment réaliste pour que le système continue de fonctionner. Un nom, un email, un numéro de carte, un IBAN, une date de naissance ou un identifiant client peuvent être transformés de façon à garder le même format, la même longueur approximative, parfois même la même logique métier.
L’intérêt est évident dans un SI: on évite de diffuser les vraies informations tout en conservant des jeux de données utilisables. C’est particulièrement utile quand une équipe a besoin de tester un parcours, de valider un traitement ou d’explorer des données sans intervenir directement sur la base de production. Le point important, c’est que le masquage protège l’usage, pas seulement l’affichage.
Il faut aussi être lucide sur ses limites. Un masque bien fait réduit fortement l’exposition, mais il ne remplace pas le contrôle d’accès, ni le cloisonnement des environnements, ni la surveillance des flux. Si une personne peut toujours interroger la donnée réelle par un autre chemin, le masque ne fait que déplacer le problème. C’est cette nuance qui change tout dans un projet sérieux, et elle mène naturellement à la question des contextes où cette technique apporte le plus de valeur.
Dans quels cas il apporte le plus de valeur
Dans les projets SI, je vois revenir les mêmes besoins. Le masquage n’est pas une solution universelle, mais il excelle dans quelques scénarios très concrets.
- Développement et tests : les équipes ont besoin de données crédibles pour vérifier des règles métier, des interfaces ou des traitements batch sans travailler sur des données réelles.
- Recette et préproduction : le métier veut retrouver des situations proches du réel pour valider un parcours client, un calcul ou un reporting.
- Analytique et data sandbox : les analystes doivent pouvoir étudier des tendances sans manipuler les valeurs exactes d’une personne.
- Support et opérations : les équipes de support peuvent résoudre un incident sans voir l’intégralité des données sensibles.
- Partage avec des prestataires : on peut transmettre un extrait exploitable à un sous-traitant, à condition que le besoin ne requière pas la donnée brute.
- Préparation de jeux pour l’IA : si le modèle n’a pas besoin de la vérité individuelle, on peut réduire le risque de fuite en préparant des données masquées.
Le vrai critère de décision est simple: si l’usage exige la valeur exacte, le masquage ne suffit pas. Si l’usage exige surtout le format, la structure et la cohérence, il devient souvent la solution la plus pragmatique. Une fois ce besoin clarifié, il faut choisir la forme de masquage la plus adaptée au système.
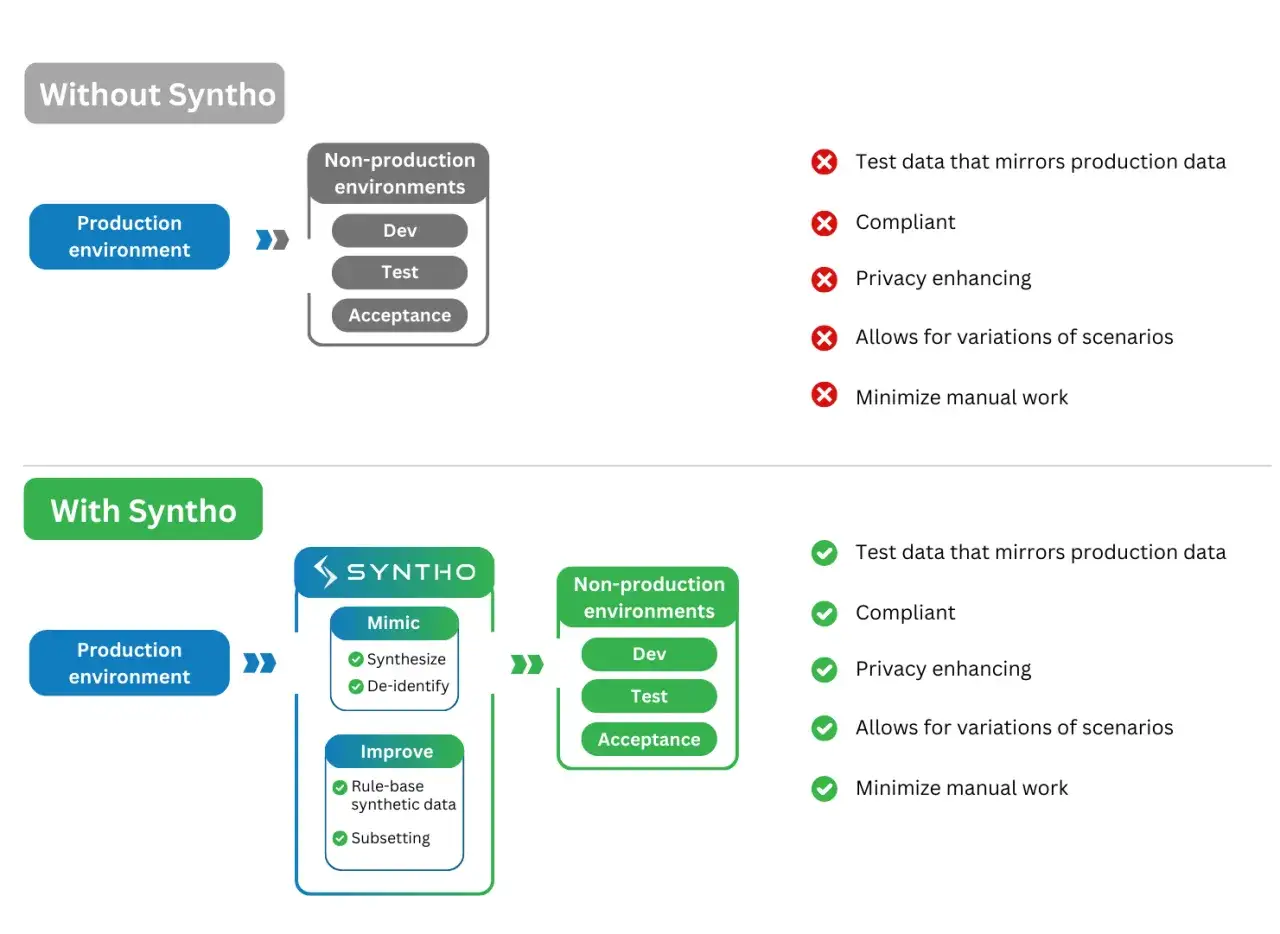
Les principales formes de masquage à connaître
On parle souvent du masquage comme d’un bloc homogène, alors qu’en pratique il existe plusieurs approches. La plus utile consiste à distinguer ce qui change la donnée à l’avance et ce qui la masque au moment de la consultation.
| Approche | Principe | Atouts | Limites | Quand je la privilégie |
|---|---|---|---|---|
| Masquage statique | On fabrique une copie de données avec des valeurs fictives, puis on travaille sur cette copie. | Très adapté aux tests, à la préproduction et aux extractions partagées. | Il faut gérer la copie, les mises à jour et la cohérence entre jeux de données. | Quand je peux préparer un dataset dédié avant usage. |
| Masquage dynamique | La donnée stockée ne change pas, mais la valeur affichée est masquée selon le rôle ou le contexte. | Pratique en production pour limiter l’exposition sans recréer toute la base. | Ne protège pas contre tous les accès autorisés et dépend beaucoup du moteur ou de la plateforme. | Quand je dois réduire la visibilité sans modifier la donnée source. |
| Masquage cohérent | La même valeur d’origine produit toujours la même valeur masquée. | Garde les jointures, les comparaisons et certains usages analytiques. | Peut créer des motifs répétitifs si les règles sont trop simples. | Quand l’intégrité référentielle doit rester intacte. |
Le terme intégrité référentielle désigne simplement le fait que les relations entre tables restent valides: un client masqué reste lié à ses commandes, un compte reste lié à ses mouvements. Sans cela, le jeu de données devient vite inutilisable. Microsoft Learn précise d’ailleurs que, dans le masquage dynamique, les données de la base ne sont pas modifiées et que la règle s’applique surtout au résultat des requêtes.
Ce détail compte, parce qu’un masquage qui casse les relations ou les filtres métier finit souvent rejeté par les équipes. Le bon choix n’est donc pas seulement technique, il dépend aussi de la manière dont les données sont consommées au quotidien. C’est précisément ce qui distingue le masquage des autres mécanismes de protection.
Ce qui le distingue de l’anonymisation, de la pseudonymisation et du chiffrement
Les quatre notions sont proches dans l’esprit, mais elles ne répondent pas au même besoin. Je conseille toujours de les séparer clairement, sinon les discussions deviennent vite floues et les arbitrages faux.
| Technique | Objectif principal | Réversibilité | Point de vigilance |
|---|---|---|---|
| Masquage | Rendre la donnée exploitable sans exposer la valeur réelle. | Parfois partielle selon la méthode utilisée. | Ne pas le confondre avec une barrière d’accès complète. |
| Pseudonymisation | Remplacer les identifiants directs par des identifiants indirects. | Oui, par conception. | Les données restent personnelles. |
| Anonymisation | Empêcher l’identification d’une personne. | Non, en principe. | Exige un niveau de transformation bien plus élevé. |
| Chiffrement | Protéger la donnée contre la lecture sans clé. | Oui, avec la clé adéquate. | Ne répond pas à lui seul au besoin de valeur réaliste pour les tests. |
La CNIL rappelle que la pseudonymisation permet de traiter des données sans identifier directement les personnes, mais qu’elle reste réversible et conserve donc un caractère personnel. C’est une distinction utile en France, surtout quand un projet SI mélange protection opérationnelle et conformité RGPD. Mon conseil est simple: si votre besoin est de partager, tester ou analyser sans montrer la donnée brute, vous êtes dans le masquage; si votre objectif est de sortir du champ des données personnelles, vous entrez dans un autre cadre.
Une fois cette frontière posée, la vraie question devient: comment l’implémenter sans casser les usages métiers ni créer de fausses sécurités?
Mettre en place un masquage sans casser le système
La méthode la plus fiable commence rarement par l’outil. Je commence presque toujours par la cartographie des données sensibles, parce qu’un masque mal ciblé est soit insuffisant, soit inutilement lourd.
- Identifier les champs sensibles : identité, contact, finance, santé, identifiants internes, journaux applicatifs, exports et pièces jointes.
- Qualifier les usages : qui consomme la donnée, à quelle fréquence, avec quel niveau de précision.
- Définir le niveau de transformation : suppression partielle, substitution réaliste, généralisation, décalage de dates, randomisation ou cohérence déterministe.
- Préserver les règles métier : mêmes formats, mêmes contraintes, relations valides, références stables.
- Tester avec les vrais consommateurs : développeurs, analystes, support, métier, sécurité.
- Documenter les exceptions : qui peut voir l’original, dans quel contexte, avec quel contrôle et quelle traçabilité.
Dans un projet mature, je recommande aussi de prévoir une stratégie de rafraîchissement. Un jeu masqué vieillit vite si les schémas évoluent, si de nouvelles colonnes apparaissent ou si les règles de jointure changent. Le masque doit donc être traité comme un composant vivant du SI, pas comme une opération ponctuelle. Cette logique de maintenance explique aussi pourquoi certaines erreurs reviennent si souvent.
Les erreurs qui donnent une fausse impression de sécurité
Le masquage échoue rarement par absence d’idée. Il échoue plutôt parce qu’on protège un endroit et qu’on oublie les autres. Les erreurs suivantes sont celles que je rencontre le plus souvent.
- Masquer seulement l’interface : si les exports, les logs ou les APIs exposent encore les données brutes, le problème reste entier.
- Oublier les copies annexes : sauvegardes, entrepôts, fichiers intermédiaires, environnements d’intégration et caches.
- Rompre les relations entre données : un masque aléatoire sur les clés de référence peut rendre les tests inutilisables.
- Utiliser un masque dynamique comme un contrôle d’accès : c’est une aide, pas un mur de sécurité.
- Trop simplifier les règles : si tous les emails deviennent des chaînes évidentes ou tous les noms suivent le même motif, la réidentification devient plus facile.
- Masquer sans tester les requêtes réelles : une donnée “jolie” mais impossible à filtrer n’aide personne.
Il y a aussi un excès inverse: masquer trop fort. Quand les équipes passent leur temps à corriger des jeux de test devenus absurdes, elles finissent par contourner la règle. Un bon dispositif protège sans étouffer l’exploitation. C’est ce juste milieu qui mérite d’être cadré avant de généraliser la méthode.
Les derniers contrôles qui font la différence avant de le généraliser
Avant de déployer le masquage à grande échelle, je vérifie toujours quatre choses: la gouvernance, la traçabilité, la qualité fonctionnelle et la capacité à maintenir les règles dans le temps. Si l’une de ces briques manque, le dispositif tient souvent quelques mois, puis se dégrade.
Premièrement, il faut savoir qui définit les règles et qui les valide. Un masque appliqué sans propriétaire finit vite incohérent. Deuxièmement, il faut savoir où l’original reste visible et qui peut y accéder. Troisièmement, il faut mesurer l’impact sur les usages métiers, surtout quand les données servent aux contrôles, au pilotage ou à la détection d’incidents. Quatrièmement, il faut automatiser le plus possible, sinon chaque changement de schéma relance le risque.
En pratique, le masquage devient vraiment utile quand il est pensé comme une pièce de la sécurité globale du SI, et pas comme une rustine. Quand il est bien cadré, il permet de travailler plus vite, de partager plus sereinement et de réduire l’exposition sans casser la valeur des données. C’est exactement le type de compromis que je cherche dans un système d’information bien gouverné.