Les points décisifs à connaître avant d’utiliser SQL Server dans un SI
- Le moteur sépare clairement les fichiers de données et le journal, et cette distinction change tout pour la reprise après incident.
- Le bon choix de récupération dépend d’abord du RPO et du RTO, pas d’une préférence théorique.
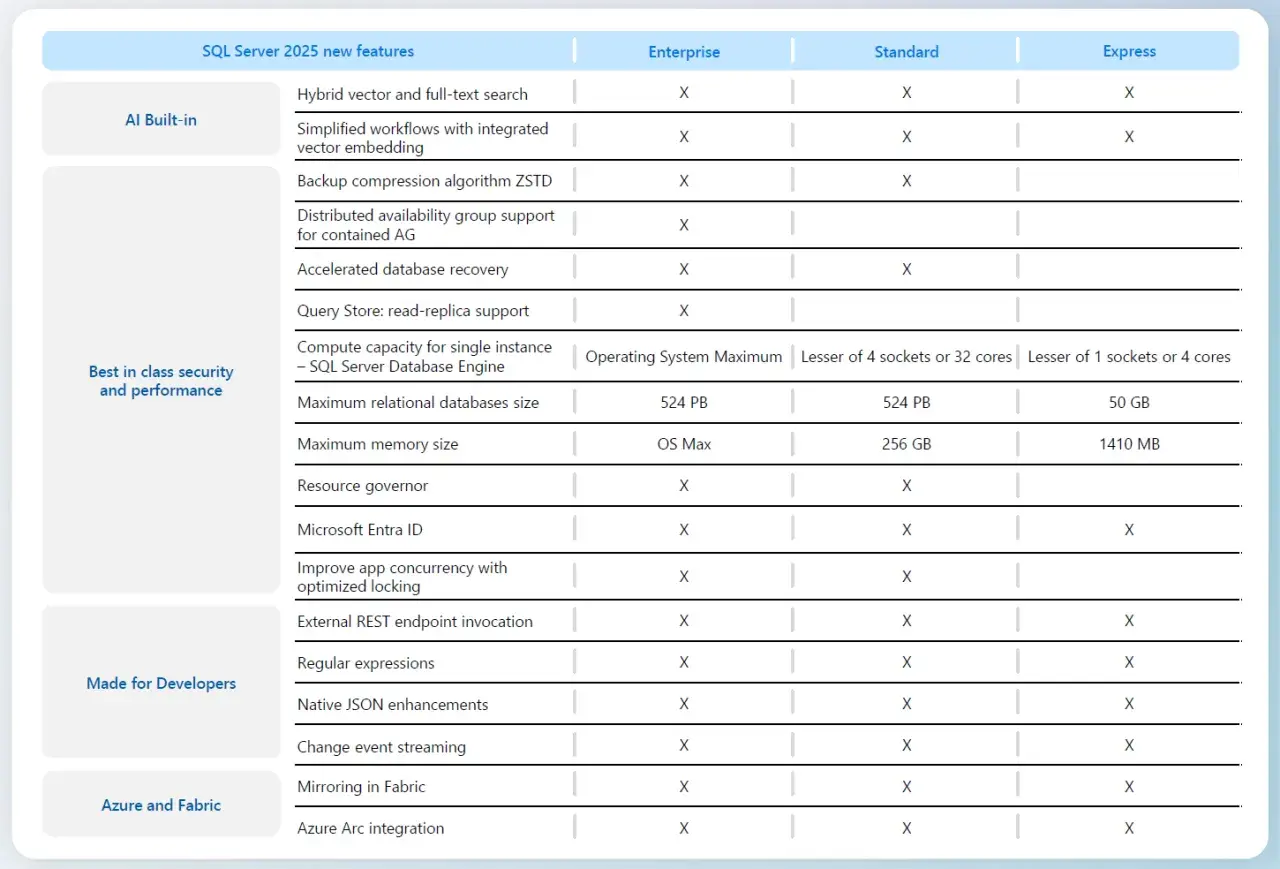
- Express, Standard, Enterprise et Developer ne visent pas le même niveau de charge ni le même budget d’exploitation.
- La performance se joue souvent sur le schéma, les contraintes et les index avant même d’ouvrir la console d’administration.
- La sécurité repose sur des droits mesurés, des sauvegardes protégées et des tests de restauration réels.
Ce qu’est vraiment SQL Server dans un SI
Dans la pratique, SQL Server est le moteur relationnel de Microsoft qui stocke, interroge et sécurise les données via T-SQL, tandis que SSMS reste l’interface la plus courante pour administrer une instance, créer des objets et lire les plans d’exécution. Ce n’est pas un simple “dépôt de tables” : c’est une brique d’infrastructure qui porte une partie de la logique de confiance du système.
Je le vois souvent au centre de trois besoins très concrets : enregistrer des transactions fiables, servir des applications métier en ligne et alimenter des rapports sans réécrire toute l’architecture. Si votre SI mélange gestion opérationnelle, historique et reporting, le vrai sujet n’est donc pas “faut-il un SGBD ?”, mais “quel niveau d’exploitation et de gouvernance faut-il prévoir ?”.
Cette nuance compte, parce qu’un moteur bien choisi mais mal cadré produit vite l’effet inverse de celui recherché. C’est précisément pour cela que je regarde d’abord la structure physique des fichiers avant de parler performance.
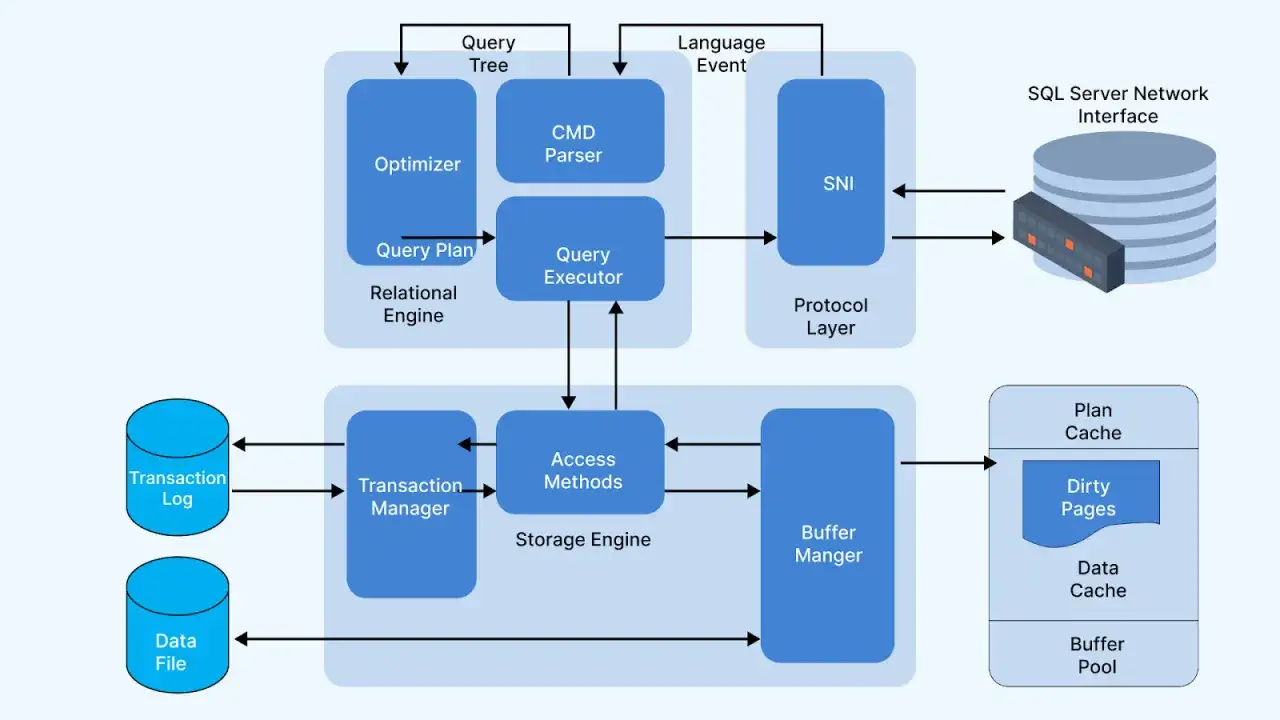
Comment le moteur organise les données sur disque
Le socle est assez simple, mais on oublie vite ce qui le rend fiable : les données d’un côté, le journal de l’autre. Une base vit en général avec un fichier de données principal, éventuellement des fichiers secondaires, et un fichier journal séparé; cette séparation permet de rejouer les transactions et de remettre la base dans un état cohérent après incident.
En règle générale, une base fonctionne très bien avec un fichier de données et un fichier journal uniques. Les fichiers supplémentaires et les filegroups servent à répartir la charge, à organiser des volumes importants ou à mieux maîtriser certains scénarios d’exploitation, mais ils ne sont pas obligatoires pour une architecture saine.
| Base système | Rôle concret | Pourquoi je la surveille |
|---|---|---|
master |
Contient les informations d’instance et les métadonnées de niveau serveur. | Si elle est corrompue ou mal sauvegardée, l’instance elle-même devient difficile à reconstruire. |
model |
Modèle utilisé comme base de création pour les nouvelles bases. | Une modification ici se propage aux bases créées ensuite, parfois sans qu’on s’en rende compte. |
msdb |
Stocke notamment les jobs, alertes et historiques liés à l’exploitation. | Quand l’automatisation est importante, c’est une base critique au quotidien. |
tempdb |
Espace de travail pour les objets temporaires et certains traitements intermédiaires. | Elle absorbe facilement les effets d’une mauvaise charge ou d’un tri massif mal anticipé. |
Resource |
Base système en lecture seule contenant des objets système. | Elle n’est pas souvent modifiée, mais elle fait partie du cœur technique du moteur. |
Quand je prépare une instance, je commence presque toujours par tempdb et model. La première révèle vite les problèmes de charge, la seconde peut contaminer toute la chaîne de création si elle est négligée. Une fois cette mécanique comprise, la vraie question devient celle de la récupération après incident.
Sauvegarder et restaurer sans improviser
La sauvegarde n’est pas une assurance symbolique, c’est une procédure qui doit être testée. Microsoft rappelle qu’une stratégie de sauvegarde n’a de valeur que si l’on vérifie réellement la restauration, l’intégrité des fichiers et la capacité à revenir à un état exploitable.
Je pars toujours de deux indicateurs : le RPO (la perte de données maximale acceptable) et le RTO (le temps de reprise tolérable). Une fois ces deux chiffres fixés, le choix du modèle de récupération devient beaucoup plus clair.
| Modèle de récupération | Journal | Sauvegarde du journal | Restauration | Cas d’usage |
|---|---|---|---|---|
| Simple | Le journal est réutilisé automatiquement. | Non | Pas de restauration à un point précis dans le temps. | Environnements de test ou données facilement recréables. |
| Full | Le journal est conservé jusqu’à sa sauvegarde. | Oui | Restauration point-in-time possible. | Production et SI où la perte de données doit rester minimale. |
| Bulk-logged | Proche du mode full, avec certaines opérations de masse traitées différemment. | Oui | Pratique pour des charges volumineuses, avec des limites pendant les opérations bulk. | Chargements lourds ou phases ponctuelles d’import. |
Dans les projets que j’accompagne, le trio gagnant ressemble souvent à ceci : sauvegarde complète, sauvegarde différentielle si la base grossit vite, puis sauvegardes du journal quand le mode full est requis. Je garde aussi trois réflexes simples : des fichiers .BAK et .TRN clairement nommés, un stockage séparé du serveur de production, et des sauvegardes chiffrées avec la clé ou le certificat conservé hors du volume principal. Quand la reprise est cadrée, le choix de l’édition devient beaucoup plus rationnel.
Choisir l’édition sans surdimensionner le projet
Le piège classique consiste à choisir trop gros “au cas où”. En réalité, la bonne édition dépend surtout du niveau de charge, du besoin de haute disponibilité et du budget d’exploitation, pas du prestige du moteur.
| Édition | Pour qui | Repères utiles | Mon lecture pratique |
|---|---|---|---|
| Express | Apprentissage, petites applications, services légers. | Gratuite, limitée à 1 socket ou 4 cœurs, avec environ 1 410 Mo de buffer pool par instance et une base de 50 Go max. | Très bien pour démarrer ou héberger un usage simple, mais on atteint vite ses limites. |
| Standard | La majorité des applications métier de taille moyenne. | Jusqu’à 4 sockets ou 32 cœurs, 256 Go de buffer pool, et des fonctions de disponibilité suffisantes pour beaucoup de SI. | C’est souvent le meilleur compromis coût/capacité. |
| Enterprise | Charges critiques, besoins avancés de disponibilité et de performance. | Conçue pour les environnements exigeants, avec le niveau de fonctionnalités le plus large. | À réserver aux cas où Standard ne couvre plus le besoin réel. |
| Developer | Développement et test. | Fonctionnalités complètes pour travailler comme en production, mais sans usage de production. | Je la recommande souvent pour valider une architecture avant mise en service. |
| Evaluation | Validation ou démonstration. | Accès temporaire, généralement 180 jours. | Utile pour tester un scénario complet, mais pas pour une exploitation durable. |
La vraie question n’est donc pas “quelle édition est la meilleure ?”, mais “quelle édition absorbe le besoin réel sans créer de coût inutile”. Une fois ce point verrouillé, le moteur ne donnera pourtant de bons résultats que si le schéma et les requêtes suivent.
Modéliser et indexer sans casser les performances
Avant d’optimiser, je commence par le modèle. Une base propre s’appuie sur des clés primaires, des clés étrangères, des types adaptés et des contraintes qui empêchent les incohérences avant qu’elles n’entrent dans le système. C’est moins spectaculaire qu’un réglage d’index, mais bien plus rentable sur la durée.
- Je choisis le type de donnée le plus serré possible, au lieu de réserver des tailles “au cas où”.
- J’utilise les clés primaires et étrangères pour imposer l’intégrité référentielle.
- J’ajoute des contraintes
UNIQUEetNOT NULLquand elles reflètent vraiment la règle métier. - Je normalise les tables transactionnelles, puis je ne dénormalise que si une mesure confirme le gain.
- J’indexe les colonnes réellement utilisées dans les filtres, les jointures et les tris fréquents.
Un index est une structure sur disque qui accélère la recherche des lignes; en revanche, trop d’index ralentissent INSERT, UPDATE et DELETE. Pour voir ce que le moteur utilise vraiment, j’ouvre le plan d’exécution dans SSMS et je m’appuie aussi sur Query Store, qui garde l’historique des plans et permet de repérer les régressions sans deviner.
columnstore et les traitements en masse prennent souvent l’avantage. Autrement dit, le bon design dépend du profil de charge, pas d’une recette unique.
Sécuriser les accès et garder l’exploitation simple
La sécurité se joue à plusieurs niveaux : plateforme, authentification, objets et applications. Je préfère raisonner en “surface d’attaque minimale” plutôt qu’en accumulation de comptes et de droits, parce que c’est là que les dérives deviennent coûteuses à corriger.
Je conseille une logique de moindre privilège : on donne seulement les droits nécessaires, ni plus ni moins. Les rôles et les sécurables servent précisément à ça, et c’est bien plus propre que d’empiler des permissions au cas par cas. En pratique, je surveille surtout les accès, les jobs planifiés, les sauvegardes et les comptes de service, car ce sont souvent les premiers points de fragilité.
Le chiffrement complète cette logique, mais ne la remplace pas. Il protège les données si une machine ou une sauvegarde tombe entre de mauvaises mains; en revanche, il ne corrige ni un compte trop permissif ni une application mal conçue. Pour les sauvegardes, je retiens trois règles : fichier.BAK pour les sauvegardes complètes, .TRN pour les journaux, stockage séparé du serveur de production. Microsoft recommande aussi de chiffrer et, si possible, de compresser les sauvegardes, tout en gardant une copie du certificat ou de la clé ailleurs que le fichier chiffré.
En 2026, SSMS 22.7.1 est la version GA actuelle; je le garde comme outil d’administration de référence pour vérifier les droits, les jobs, les sauvegardes et les plans. Avec ces garde-fous en place, on évite déjà la plupart des incidents évitables.
Les quatre réflexes qui évitent les mauvaises surprises en production
Quand je dois cadrer une base de données SQL Server pour un SI, je commence toujours par quatre questions : quelles données sont critiques, quel RPO et quel RTO sont acceptables, quelle édition suffit vraiment et comment je teste la restauration. Si l’une de ces réponses manque, le projet paraît avancé sur le papier mais reste fragile en production.Le reste suit presque naturellement : un schéma clair, des index mesurés, des sauvegardes chiffrées et restaurées pour de vrai, puis une sécurité simple à maintenir. C’est ce socle qui rend SQL Server fiable, pas la multiplication des options ou des outils.
La bonne approche n’est pas de tout activer, mais de faire correspondre le moteur au besoin réel du SI, puis de le surveiller avec méthode au lieu de compter sur la chance.