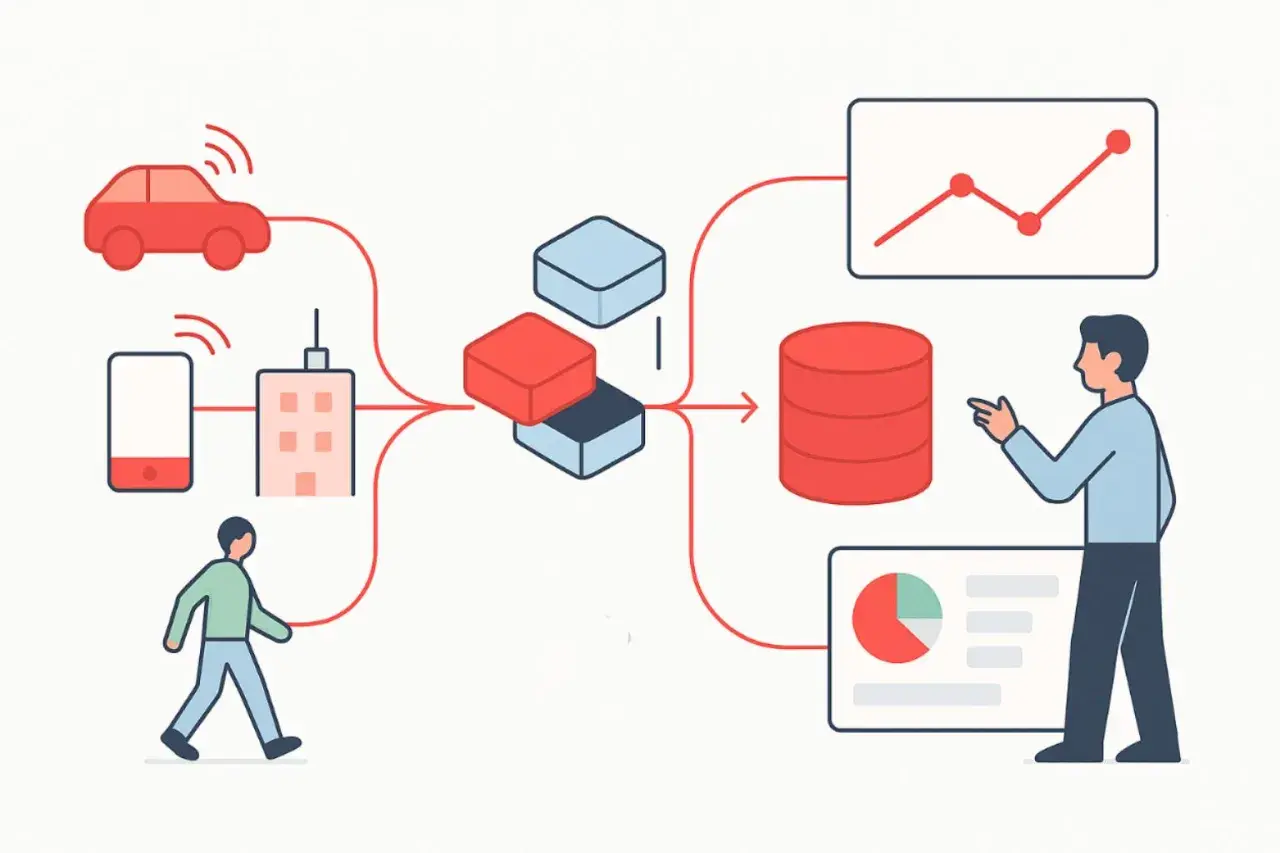
Un système d’information solide ne sert pas seulement à stocker des fichiers ou à faire tourner quelques logiciels. Il relie le matériel, les applications, les réseaux et les règles de circulation de la donnée pour que l’information reste fiable, accessible et exploitable.
Je vais aller droit au but : ce que recouvre un SI centré sur la donnée, comment la donnée y circule, pourquoi la gouvernance compte autant que la technique, et quels réflexes évitent les projets fragiles ou trop coûteux à maintenir.
Les points clés à garder en tête avant de travailler un SI centré sur la donnée
- Un SI est un ensemble technique et organisationnel, pas seulement un logiciel ou une base de données.
- La valeur d’une donnée dépend autant de sa qualité que de sa disponibilité et de sa traçabilité.
- Les flux d’échange ne se traitent pas tous de la même façon : API, traitements par lots et temps réel répondent à des besoins différents.
- La gouvernance évite les doublons, les définitions contradictoires et les tableaux de bord incohérents.
- La sécurité et la conformité doivent être conçues dès le départ, pas ajoutées après coup.
- Une architecture hybride est souvent plus réaliste qu’un modèle totalement centralisé ou totalement distribué.
Ce qu’un système d’information fait vraiment circuler
Pour moi, la bonne définition est simple : un système d’information fait circuler de la donnée entre des personnes, des outils et des processus. Le matériel fournit la capacité, les logiciels donnent les fonctions, le réseau transporte, et les règles métier donnent le sens. Sans cette couche de sens, on a seulement des volumes de données, pas un système utile.
| Brique | Rôle concret | Si elle est mal pensée |
|---|---|---|
| Matériel | Serveurs, postes, stockage, périphériques, équipements réseau | Ralentissements, pannes, capacité insuffisante |
| Logiciels | ERP, CRM, outils métiers, bases de données, BI, plateformes data | Données dispersées, interfaces fragiles, doublons fonctionnels |
| Réseau | Connexion entre sites, applications, API, services cloud | Temps de réponse instables, échanges incomplets, dépendances invisibles |
| Données | Référentiels, données transactionnelles, données analytiques, logs | Indicateurs faux, pertes de confiance, décisions mal orientées |
| Processus | Règles de validation, circuits de contrôle, responsabilités | Chaînes de traitement incohérentes, erreurs répétées |
Le point de vigilance, c’est la cohérence entre ces briques. Un CRM peut être excellent, mais s’il ne parle pas correctement au logiciel de facturation ou au data warehouse, la donnée se fragmente et les équipes finissent par ne plus savoir quelle version croire. C’est précisément ce qui prépare la question suivante : comment la donnée circule-t-elle d’une source à l’autre sans se dégrader ?
Comment la donnée passe d’une source à un usage utile
Je regarde souvent la donnée comme un trajet. Elle naît dans une application métier, traverse une zone d’intégration, est contrôlée, enrichie, stockée, puis exposée dans un tableau de bord, un moteur de recommandation ou un outil de pilotage. À chaque étape, elle peut gagner en valeur, ou perdre en fiabilité.
Le chemin le plus courant
Dans une organisation classique, la chaîne ressemble à ceci : collecte, ingestion, stockage, transformation, restitution. La collecte récupère la donnée depuis une saisie, une transaction, un capteur ou un flux externe. L’ingestion la fait entrer dans le SI. La transformation la nettoie, la normalise et la rapproche d’autres jeux de données. La restitution l’expose aux métiers sous une forme exploitable.
Batch, API et temps réel
Les traitements par lots, ou batch, conviennent quand on peut regrouper des données à intervalles réguliers. Une API est une interface qui permet à deux applications d’échanger de manière structurée. Le temps réel, lui, sert quand la latence compte : validation d’un paiement, détection d’une anomalie, mise à jour d’un stock. En pratique, on ne choisit pas un modèle par effet de mode ; on le choisit selon le besoin métier. Un site éditorial peut très bien vivre avec des lots nocturnes pour ses statistiques, alors qu’une plateforme de vente ne peut pas se permettre d’avoir un stock en retard.
Lire aussi : Delta Tables - Le data lake enfin fiable et ACID ?
Les points de casse les plus fréquents
- Des noms de champs différents pour la même notion.
- Des formats qui ne s’alignent pas entre applications.
- Des doublons créés par des importations successives.
- Des horodatages incohérents, surtout quand plusieurs zones ou systèmes cloud sont en jeu.
- Des règles métier connues d’une équipe, mais jamais documentées.
La conclusion est simple : plus le flux est complexe, plus la qualité doit être pensée au niveau du système, pas au niveau d’un fichier isolé. C’est là qu’intervient la gouvernance.
Pourquoi la gouvernance des données change tout
La gouvernance, ce n’est pas de la bureaucratie en plus. C’est la manière de décider qui crée quoi, qui valide, qui corrige, et quelles règles s’appliquent à tout le monde. Sans elle, chaque équipe invente sa logique, et la donnée perd en fiabilité aussi vite qu’elle gagne en volume.
France Num rappelle que la gestion des données consiste à collecter, stocker, organiser et tenir à jour l’information d’une entreprise. Je trouve cette définition utile parce qu’elle replace le sujet dans le concret : un SI n’est pas seulement un stock, c’est un mécanisme de pilotage.
- Propriétaire de donnée : la personne ou l’équipe qui arbitre la définition et l’usage d’une donnée.
- Data steward : le relais opérationnel qui surveille la qualité et les règles de gestion.
- Dictionnaire de données : le document qui fixe le sens des champs et des indicateurs.
- Catalogue de données : l’inventaire des jeux de données, de leurs usages et de leurs responsables.
- Master Data Management : la gestion des données de référence pour éviter les versions contradictoires d’un même client, produit ou fournisseur.
Je suis particulièrement attentif à trois signaux d’alerte : plusieurs versions d’un même client, des définitions d’indicateurs qui changent selon les services, et des corrections de données faites “à la main” sans trace ni règle commune. La bonne réponse n’est pas de multiplier les réunions, mais de poser des standards simples, des contrôles dès la saisie, et un référentiel unique quand c’est pertinent. Le sujet est d’ailleurs très lié à la sécurité, parce qu’une donnée bien gouvernée est aussi une donnée plus facile à protéger.
Sécurité et conformité ne sont pas un bloc séparé
La sécurité des données n’arrive pas après la conception du SI : elle en fait partie. Je parle ici d’accès, de journalisation, de sauvegarde, de chiffrement, de segmentation réseau, mais aussi de règles humaines comme la gestion des droits et la sensibilisation des équipes. Quand ces éléments sont absents, le meilleur outil du monde devient vite un point faible.
La CNIL a élargi son guide de sécurité aux usages cloud, API, applications mobiles et IA. C’est cohérent avec le terrain : les risques viennent de plus en plus des échanges entre systèmes, pas seulement du poste de travail. Dès qu’une donnée personnelle circule, il faut penser minimisation, durée de conservation, preuve des accès et capacité à réagir en cas d’incident.
- Contrôle d’accès : chacun ne voit que ce dont il a besoin.
- Authentification forte : le mot de passe seul ne suffit plus dans les environnements sensibles.
- Chiffrement : la donnée reste illisible si elle est interceptée.
- Journalisation : on garde une trace des actions importantes pour investiguer plus vite.
- Sauvegardes : elles protègent contre les erreurs humaines, les incidents techniques et certains ransomwares.
- Plan de reprise : il précise comment redémarrer après une panne ou une attaque.
Je regarde aussi le duo RPO/RTO : le premier indique la perte de données maximale acceptable, le second le délai maximum de remise en service. Ces deux notions évitent les fausses promesses, parce qu’elles forcent à décider ce que l’organisation est réellement prête à perdre et combien de temps elle peut rester à l’arrêt. Une fois ce cadre posé, le vrai sujet devient le choix d’architecture.
Choisir une architecture qui tient dans la durée
Il n’existe pas un modèle parfait, seulement des compromis plus ou moins adaptés. Un SI centralisé simplifie la cohérence, mais peut devenir rigide. Un SI distribué donne de l’autonomie aux équipes, mais demande une gouvernance beaucoup plus forte. Dans la plupart des cas, je privilégie une architecture hybride, parce qu’elle équilibre mieux les besoins métier et les contraintes techniques.
| Modèle | Atout principal | Limite principale | Quand je le recommande |
|---|---|---|---|
| Centralisé | Une source de vérité claire | Peu de souplesse | Quand la cohérence prime sur la vitesse d’évolution |
| Distribué | Autonomie des équipes | Risque de fragmentation | Quand plusieurs métiers avancent à des rythmes très différents |
| Hybride | Bon compromis entre contrôle et agilité | Nécessite des règles claires d’interopérabilité | Quand on veut évoluer sans casser l’existant |
Avant de valider une solution, je vérifie quatre choses : l’interopérabilité avec les autres outils, la qualité des référentiels, la capacité à monter en charge, et le coût total de possession, c’est-à-dire le coût réel sur toute la durée de vie de la solution, pas seulement le prix d’achat. Les erreurs classiques sont connues : acheter l’outil avant d’avoir défini les règles, automatiser des données sales, multiplier les silos applicatifs et sous-estimer le travail de migration.
Si le besoin principal est le reporting, une architecture plus simple peut suffire. Si l’enjeu est l’activation commerciale, la personnalisation ou l’IA, il faut souvent une base plus propre, des flux mieux tracés et une gouvernance plus ferme. Quand ce cadre est clair, on peut enfin parler de maturité réelle du SI.
Le contrôle que je fais avant de considérer un SI prêt pour la donnée
Avant de parler de performance ou d’IA, je pose toujours les mêmes questions simples : peut-on identifier la source d’une donnée, sait-on qui la modifie, peut-on la tracer, et sait-on quoi faire si elle devient fausse ? Si la réponse est floue, le projet n’est pas mûr, même si les écrans sont élégants.
- La donnée a-t-elle un propriétaire clairement identifié ?
- Les définitions des indicateurs sont-elles partagées entre les équipes ?
- Les contrôles de qualité sont-ils intégrés au processus, et non ajoutés après coup ?
- Les accès sont-ils limités par rôle et revus régulièrement ?
- Le SI sait-il absorber une montée en charge sans perdre la cohérence des données ?
- Un incident peut-il être analysé rapidement grâce à des logs et à un historique fiable ?
Un SI vraiment exploitable n’est pas celui qui accumule le plus de fonctions, mais celui qui garde la donnée lisible, sûre et utile au moment où on en a besoin. Si je devais résumer l’esprit d’un bon projet data, je dirais ceci : partir des usages, verrouiller la qualité, documenter les règles, puis sécuriser l’ensemble sans alourdir inutilement les équipes.