Quand les données sont éparpillées entre plusieurs domaines métier, le vrai problème n’est pas seulement technique : c’est la manière dont le SI organise la responsabilité, la qualité et l’accès. L’approche de data mesh architecture répond à cette tension en distribuant la propriété des données tout en gardant des règles communes. Je vais montrer ce que ce modèle change vraiment, dans quels cas il apporte un gain net, et comment le mettre en place sans transformer le chantier en usine à gaz.
Les points qui comptent vraiment avant de changer d’architecture
- Le modèle décentralise la responsabilité par domaine métier, au lieu de tout faire remonter à une équipe data unique.
- Il fonctionne si les données sont traitées comme des produits, avec un propriétaire, des règles d’accès et une qualité mesurable.
- Une plateforme self-service évite que chaque équipe recrée ses pipelines, son stockage et ses contrôles.
- La gouvernance ne disparaît pas : elle devient fédérée, avec des standards communs et des automatisations.
- Il est plus pertinent dans un SI complexe, multi-domaines, que dans une organisation encore petite ou très centralisée.
Ce que ce modèle change dans un SI data
Dans beaucoup d’organisations, le schéma classique reste le même : une équipe centrale collecte, nettoie, consolide, puis redistribue les données vers le reste de l’entreprise. Ce modèle tient tant que les usages sont simples. Dès que les équipes se multiplient, que les besoins changent vite et que les sources se diversifient, la file d’attente s’allonge. Tout passe par le même goulot d’étranglement, et chaque demande métier devient une petite négociation.
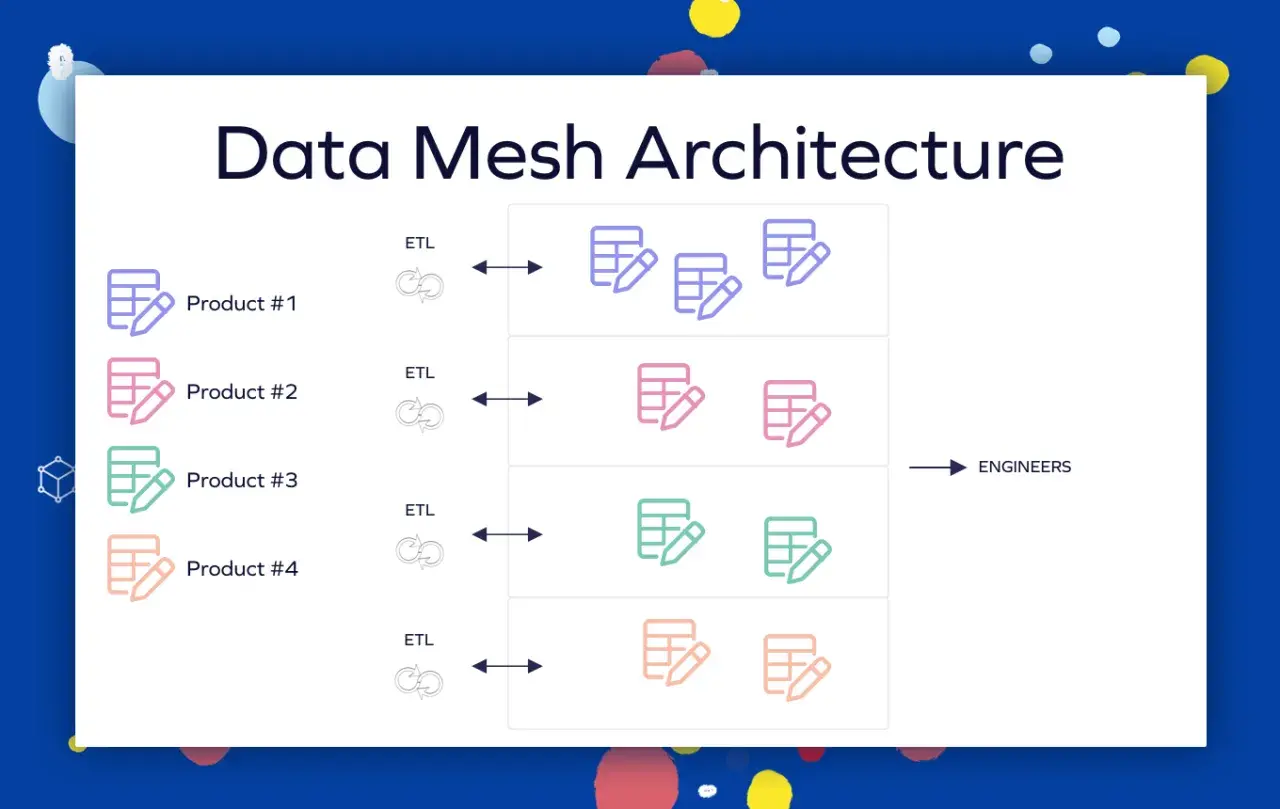
Le data mesh inverse cette logique. On ne demande plus à une seule équipe de porter toute la charge. On confie la responsabilité des données à ceux qui connaissent le mieux le domaine concerné. Autrement dit, le marketing, la logistique, le risque ou la relation client ne produisent pas seulement des opérations métier ; ils deviennent aussi responsables des jeux de données qui décrivent leur réalité.
Ce changement est plus profond qu’il n’y paraît. Il modifie la propriété des données, la manière de publier les flux, la façon de documenter les usages, et même la définition de la qualité. Dans un SI orienté mesh, je ne me contente pas de demander si une table existe. Je demande aussi qui en est responsable, à quelle fréquence elle est mise à jour, comment elle est découverte, et quel engagement de service l’accompagne.
En pratique, trois effets apparaissent vite. D’abord, les changements locaux restent locaux : une modification dans le domaine commandes ne casse pas forcément tout le reste. Ensuite, les équipes consommatrices parlent plus directement aux équipes productrices, ce qui réduit les malentendus. Enfin, le SI cesse d’être organisé autour d’un centre unique et devient un ensemble de domaines coordonnés. C’est cette redistribution de responsabilité qui rend les quatre principes indispensables.
Les quatre principes qui rendent le modèle exploitable
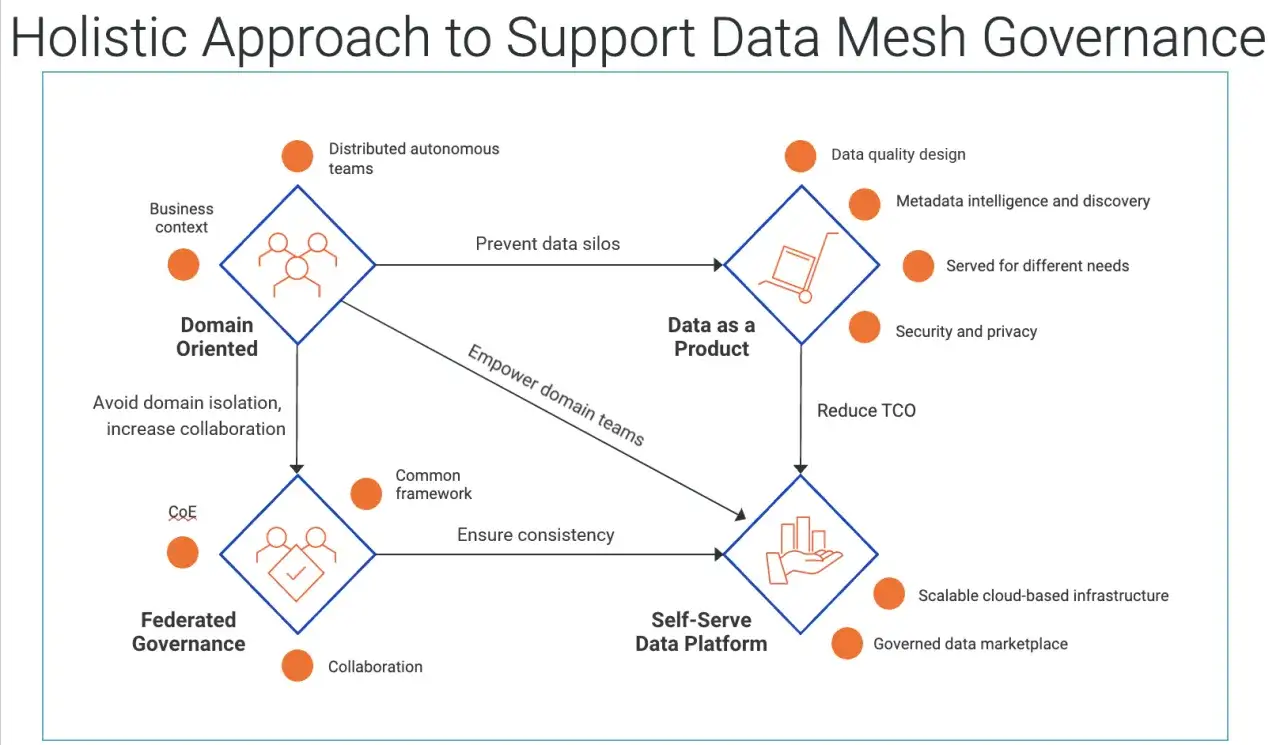
Sans ces quatre piliers, on obtient souvent un simple découpage organisationnel, pas un vrai mesh. Le point important n’est pas de répéter le vocabulaire à la mode, mais de comprendre l’effet opérationnel de chaque principe.
Des domaines responsables de leurs données
Le premier pilier consiste à aligner la responsabilité technique sur les domaines métier. Un domaine n’est pas un service informatique abstrait ; c’est une zone de sens business, avec ses règles, ses indicateurs et ses consommateurs. Cette proximité change tout, parce qu’elle réduit la distance entre la donnée produite et le contexte qui lui donne sa valeur.
Quand une équipe connaît le terrain, elle peut mieux définir les champs utiles, les exceptions réalistes et les seuils de qualité pertinents. C’est aussi plus rapide pour arbitrer une évolution. Je vois souvent là la différence entre un pipeline qui survit et un pipeline qui accompagne réellement le métier.
Des données traitées comme des produits
Le deuxième pilier est probablement le plus sous-estimé. Une donnée n’est plus un sous-produit technique, mais un produit interne avec des utilisateurs, des attentes et un cycle de vie. Cela implique une documentation lisible, une adresse stable, un responsable identifié, et des indicateurs de qualité qui ne se limitent pas à “ça fonctionne en prod”.
Un bon produit de données doit être discoverable, c’est-à-dire facile à trouver ; addressable, donc accessible de manière standard ; trustworthy, avec une qualité mesurable ; et self-describing, autrement dit compréhensible sans que tout le monde appelle le même expert. En langage concret, cela veut dire qu’on publie des contrats de données, des métadonnées claires, des règles de fraîcheur, et des engagements de service, souvent résumés sous le terme SLO, pour service-level objective.
Une plateforme self-service qui évite de tout reconstruire
Si chaque domaine devait inventer ses propres outils d’ingestion, de contrôle, de stockage et de publication, le modèle s’effondrerait très vite. La plateforme self-service sert justement à absorber cette complexité commune. L’idée n’est pas de tout centraliser à nouveau, mais de mutualiser ce qui peut l’être : les briques d’accès, la sécurité, le catalogage, la surveillance, l’automatisation et les garde-fous techniques.
Je résume souvent ce point ainsi : l’équipe plateforme fournit l’outillage, les équipes métier gardent la main sur leurs données. Cette séparation évite une duplication coûteuse et réduit le temps de mise à disposition d’un nouveau produit de données. C’est aussi ce qui permet au mesh de rester soutenable quand le nombre de domaines augmente.
Lire aussi : Données analytiques - Transformez-les en décisions concrètes
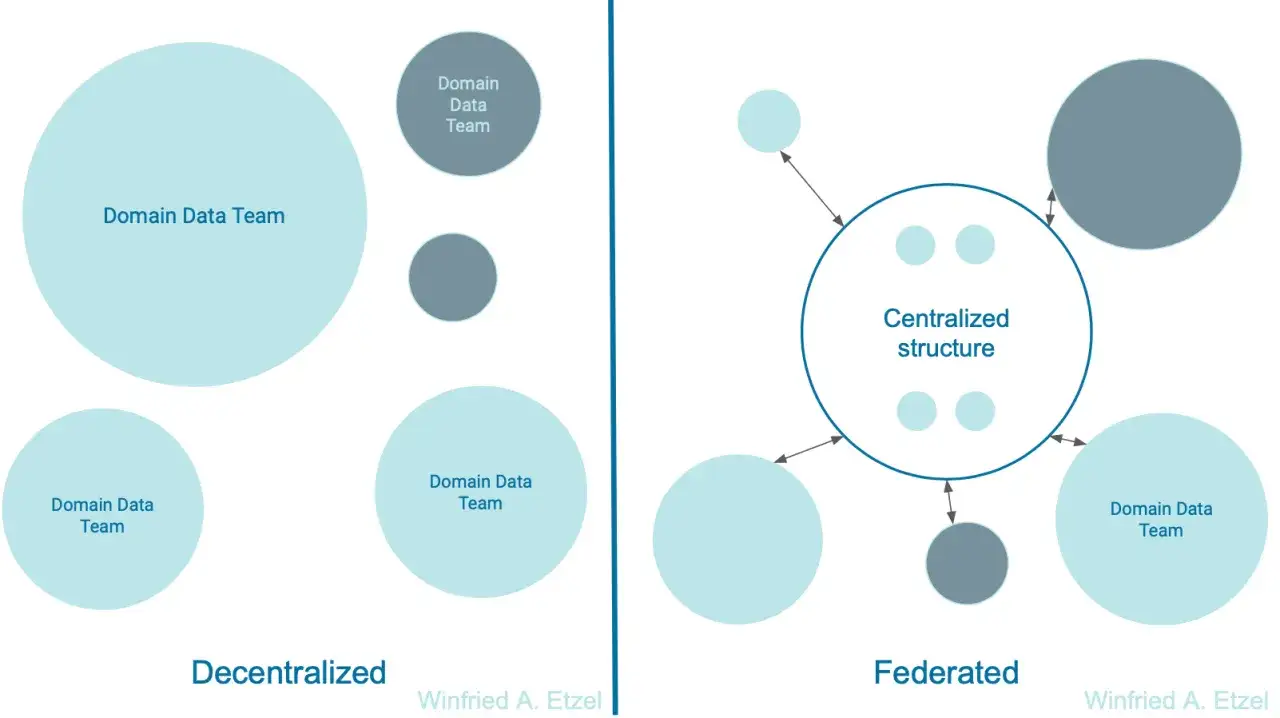
Une gouvernance fédérée plutôt qu’un contrôle manuel permanent
Le dernier pilier est celui qui sauve l’ensemble du chaos. La gouvernance fédérée fixe des règles communes, mais sans transformer chaque publication en comité de validation. On parle ici de politiques partagées, de standards de nommage, de règles de sécurité, de journaux d’audit et de contrôles automatisés. L’objectif est simple : garder la cohérence sans casser l’autonomie.
Dans les projets sérieux, la gouvernance n’est pas une salle d’attente. C’est un système de contraintes explicites, idéalement codifiées, qui s’appliquent partout de la même manière. Si cette couche reste floue, le modèle se fragilise immédiatement, car chaque domaine finit par réinventer ses propres règles. Une fois ces principes posés, la vraie question devient alors très concrète : dans quels cas ce choix vaut-il vraiment l’effort ?
Quand il faut l’adopter, et quand il vaut mieux attendre
Je ne recommande pas ce modèle par réflexe. Il est puissant, mais il a un coût organisationnel réel. Il prend tout son sens lorsque le SI n’est plus un bloc homogène et que la centralisation commence à freiner la vitesse de l’entreprise.
| Situation | Ce que j’en déduis |
|---|---|
| Plusieurs domaines métier doivent publier et consommer les mêmes données | Le besoin de partage transversal justifie une responsabilité distribuée. |
| L’équipe data centrale devient un goulot d’étranglement | Le modèle centralisé a atteint sa limite de scalabilité. |
| Les changements métier arrivent souvent et doivent être visibles vite | La proximité entre production et usage apporte un vrai gain de réactivité. |
| La qualité des données dépend fortement du contexte métier | Le domaine est mieux placé pour détecter les incohérences et les corriger. |
| Les contraintes de conformité ou d’audit sont fortes | Une gouvernance fédérée peut améliorer la traçabilité, si elle est bien instrumentée. |
À l’inverse, j’attendrais si l’organisation n’a pas encore une base minimale de gouvernance, si les équipes ne sont pas assez autonomes, ou si le patrimoine de données reste petit. Pour un périmètre de 1 ou 2 équipes, le bénéfice d’un mesh est souvent inférieur à la complexité ajoutée. Dans ce cas, un bon modèle centralisé, bien gouverné, peut être plus rationnel.
Il faut aussi garder une chose en tête : ce modèle ne sert pas à contourner le manque de maturité. Il fonctionne mieux quand on a déjà des équipes stables, une vraie culture produit et des responsabilités claires. Si ces conditions ne sont pas là, l’effort doit d’abord porter sur l’organisation, pas sur le slogan d’architecture. Pour trancher encore mieux, il faut comparer le mesh aux modèles que l’on confond le plus souvent avec lui.
Data warehouse, data lake ou data mesh
Ces trois approches ne répondent pas exactement au même besoin. Le problème apparaît quand on les mélange comme si elles étaient interchangeables. En réalité, chacune a sa logique propre, son bon périmètre et ses limites.
| Critère | Data warehouse | Data lake | Data mesh |
|---|---|---|---|
| Logique d’organisation | Centralisée et fortement modélisée | Centralisée et plus souple sur les formats | Décentralisée par domaines |
| Responsabilité | Portée par une équipe centrale | Portée par une équipe plateforme ou data centrale | Partagée entre domaines et plateforme |
| Point fort | Consolidation et reporting fiables | Volume, variété, exploration | Autonomie, scalabilité organisationnelle, proximité métier |
| Limite fréquente | Lenteur à faire évoluer le modèle | Risque de marécage de données mal gouvernées | Complexité de gouvernance et d’alignement |
| Le meilleur cas d’usage | BI standardisée et consolidation | Stockage large et usages exploratoires | Organisation multi-domaines avec besoins distribués |
Je le formule souvent ainsi : un warehouse structure, un lake stocke, un mesh distribue la responsabilité. Ce n’est pas la même bataille. Le mesh n’annule pas les deux autres ; il change la manière de les organiser et de les exploiter. Dans certains cas, un lake ou un warehouse restent d’ailleurs les bons fondements d’un projet data, à condition qu’ils ne deviennent pas une impasse organisationnelle.
La distinction avec le data fabric mérite aussi d’être claire. Le fabric cherche d’abord à unifier et orchestrer ce qui existe ; le mesh change l’ownership et les responsabilités à la source. Si le besoin principal est l’intégration, le fabric peut suffire. Si le vrai problème est la dépendance à une équipe centrale, le mesh répond mieux. Une fois cette boussole posée, il reste la partie la plus concrète : passer de l’idée à l’exécution.
Passer d’un SI centralisé à une organisation par domaines
Je préfère toujours commencer petit. Un pilote de 2 à 3 domaines suffit largement pour apprendre sans diluer l’effort. Au-delà, on passe trop vite de la preuve de valeur au déploiement chaotique.
- Cartographier les domaines utiles : je cherche des frontières métier nettes, des flux réels entre équipes et des cas d’usage qui traversent plusieurs périmètres.
- Choisir un ou deux produits de données par domaine : pas une dizaine. L’objectif est de créer des produits réellement consommés, pas une liste de promesses.
- Définir un contrat de données : schéma, fréquence de mise à jour, propriétaire, règles de qualité, règles d’accès et mode de versioning.
- Mettre en place le catalogue et la découverte : si personne ne trouve le produit, il n’existe pas vraiment.
- Automatiser la gouvernance de base : contrôle d’accès, traçabilité, validations de format, alertes sur la fraîcheur et journalisation.
- Installer un rituel de pilotage léger : un point toutes les 2 semaines suffit souvent au départ pour arbitrer sans alourdir.
Sur ce type de pilote, je regarde moins la sophistication technique que la capacité à publier vite, à documenter clairement et à résoudre les frictions sans faire remonter chaque décision à la direction technique. Si le premier produit prend moins de 5 jours ouvrés à être exposé proprement, avec un contrat lisible et un propriétaire identifié, on tient déjà quelque chose de solide. Si le délai explose, c’est souvent le signe que la gouvernance ou la plateforme n’est pas prête.
Le bon réflexe consiste donc à découpler deux chantiers : la mise en place d’une plateforme commune, et la montée en responsabilité des domaines. Les confondre ralentit tout. Les séparer permet d’avancer par incréments et d’éviter les grandes réorganisations théoriques qui n’atterrissent jamais. Une fois le pilote lancé, les vraies erreurs apparaissent assez vite, et elles sont souvent prévisibles.
Les erreurs qui font dérailler un projet
La plupart des échecs ne viennent pas de la technologie elle-même. Ils viennent d’un mauvais cadrage. J’en vois quelques-uns revenir sans cesse.
- Confondre décentralisation et absence de standards : si chaque domaine invente sa propre logique, on perd l’interopérabilité.
- Lancer trop de domaines d’un coup : le mesh n’est pas un exercice de cartographie exhaustive. Il faut apprendre sur un périmètre réduit.
- Laisser l’équipe centrale tout porter quand même : on change le vocabulaire, mais pas le modèle de charge.
- Oublier les contrats de données : sans règles explicites, les divergences de schéma et de fraîcheur reviennent très vite.
- Mesurer l’activité au lieu de mesurer l’usage : le nombre de pipelines ou de tables ne dit rien de la valeur créée.
- Installer une gouvernance trop manuelle : si chaque accès exige une validation humaine, on recrée le goulot d’étranglement initial.
Le piège le plus coûteux, à mon avis, est le faux sentiment de progrès. On a un nouveau catalogue, un nouveau vocabulaire et quelques nouveaux outils, mais l’organisation reste dépendante d’une poignée de personnes. Tant que la responsabilité n’a pas réellement changé de main, le mesh n’existe pas. C’est justement pour vérifier cela qu’il faut des métriques simples et lisibles.
Comment juger si le pilote fonctionne
Un bon pilote ne se mesure pas à l’enthousiasme du lancement, mais à la qualité des frictions qu’il élimine. Je préfère suivre quelques indicateurs concrets plutôt qu’une batterie de KPI décoratifs.
| Indicateur | Ce qu’il raconte |
|---|---|
| Délai de publication d’un produit de données | Est-ce que les domaines peuvent livrer sans dépendre d’un goulot central ? |
| Temps nécessaire pour trouver et comprendre un jeu de données | Le catalogue et la documentation sont-ils vraiment utiles ? |
| Délai d’obtention d’un accès | La gouvernance accélère-t-elle l’usage au lieu de le bloquer ? |
| Nombre d’incidents de qualité détectés en aval | La responsabilité métier améliore-t-elle la qualité en amont ? |
| Part des produits dotés d’un propriétaire et d’un SLO | Le modèle de produit est-il appliqué de façon cohérente ? |
| Réutilisation inter-domaines | Les données circulent-elles mieux entre les équipes ? |
Sur un pilote bien cadré, je m’attends surtout à voir trois choses bouger : une publication plus rapide, moins d’allers-retours pour comprendre la donnée, et une baisse nette des frictions d’accès. Si ces trois signaux ne progressent pas, il faut corriger l’organisation avant d’étendre le périmètre. Si, au contraire, ils s’améliorent régulièrement, il devient raisonnable d’élargir.
La dernière étape consiste alors à sécuriser l’extension. C’est souvent là que les projets se perdent, parce qu’ils ont prouvé qu’un petit pilote marchait, mais pas qu’il pouvait se généraliser sans perdre sa lisibilité ni sa rigueur. C’est précisément le sujet de la dernière étape.
Les garde-fous à poser avant d’élargir le pilote
Avant de passer à l’échelle, je vérifie toujours les mêmes points. S’ils ne sont pas solides, la montée en charge ne fera qu’amplifier les défauts du pilote.
- Un catalogue unique pour découvrir les produits de données et leurs propriétaires.
- Des contrats de données versionnés pour éviter les ruptures silencieuses.
- Des règles de gouvernance automatisées pour l’accès, l’audit et la conformité.
- Une responsabilité claire par domaine, sans zone grise entre équipe centrale et métiers.
- Un modèle de support qui évite de recréer un centre de service caché.
Si je devais résumer la logique de ce modèle en une phrase, je dirais ceci : il ne s’agit pas seulement de répartir les données, mais de répartir la capacité à les faire vivre correctement. C’est cette nuance qui change tout. Quand elle est comprise, l’architecture devient plus qu’un dessin technique : elle devient un vrai levier d’organisation.