
Réduire l’empreinte d’une plateforme cloud n’est pas un geste cosmétique: c’est un travail d’architecture, de mesure et d’arbitrage. Dans l’écosystème Microsoft, le green cloud prend forme quand on aligne les workloads, les outils de pilotage et les habitudes d’exploitation pour consommer moins, mieux répartir la charge et éviter le gaspillage numérique. Je vais donc aller droit au but: définir ce que cela change concrètement, montrer ce que Microsoft met à disposition, puis expliquer comment je procéderais pour une équipe basée en France.
Les points clés pour réduire l’empreinte cloud sans perdre en contrôle
- La sobriété cloud commence par la mesure des ressources, des données et du temps d’exécution.
- Dans Microsoft, Azure sert à optimiser, Microsoft 365 à suivre la suite bureautique, et Microsoft Sustainability Manager à élargir le pilotage ESG.
- Carbon optimization fournit des recommandations concrètes et des données mensuelles pour Azure.
- Le tableau de bord Emissions Impact Dashboard pour Azure est en fin de vie au 31 mars 2027, donc l’historique doit être exporté.
- Les gains les plus rapides viennent souvent du surprovisionnement, des logs trop bavards et des transferts de données inutiles.
Ce que recouvre un cloud vraiment plus sobre
Le point de départ n’est pas le fournisseur, mais l’usage. Un cloud sobre exécute uniquement ce qui apporte de la valeur, au bon niveau de capacité, avec le moins de mouvements de données possible.
Je vois trois sources de dérive qui reviennent sans cesse: le surprovisionnement, la rétention excessive des données et l’observabilité trop bavarde. Microsoft le dit clairement dans ses recommandations Azure: une charge peut rester peu chère tout en étant énergétiquement inefficace si elle multiplie les flux, les logs ou les schémas de résilience plus lourds que nécessaire. C’est pour cela que je préfère parler de sobriété numérique appliquée au cloud plutôt que de promesse verte abstraite.
- Des VM ou des conteneurs très sous-utilisés.
- Des copies de données entre régions sans besoin fonctionnel.
- Des logs conservés plus longtemps que leur valeur d’exploitation.
- Des environnements de test laissés allumés hors des heures utiles.
- Des architectures très redondantes qui ne correspondent pas au risque réel.
À partir de là, la vraie question devient moins “comment être plus vert” que “quels leviers mesurables font baisser l’empreinte sans casser la fiabilité”. C’est précisément ce qui mène à la stratégie Microsoft et à ses outils de suivi.
Pourquoi Microsoft est devenu un acteur central sur ce sujet
En 2026, la bascule est claire: Microsoft ne traite plus la durabilité comme un sujet périphérique, mais comme une couche transversale de l’exploitation cloud et de l’IA. L’entreprise affiche des objectifs lisibles: être carbon negative, water positive et zero waste d’ici 2030, puis retirer ses émissions historiques d’ici 2050. Pour un décideur cloud, ce n’est pas un détail de communication: cela influence la manière dont les datacenters, les produits et les outils de mesure sont pensés.
Ce que j’apprécie dans cette approche, c’est qu’elle ne s’arrête pas à l’infrastructure. Azure aide à optimiser l’exécution des workloads; Microsoft 365 permet de suivre la consommation côté collaboration; Microsoft Sustainability Manager sert de couche plus large pour le reporting environnemental et les besoins ESG. Microsoft pousse aussi l’idée que l’efficacité du cloud et de l’IA doit être traitée comme un axe d’ingénierie, pas comme un simple indicateur RSE.
- Les datacenters ne sont pas seulement agrandis; ils sont intégrés à une logique de soutenabilité de conception.
- Les outils de mesure sont reliés à des recommandations d’optimisation, pas seulement à des tableaux de bord passifs.
- La trajectoire produit va vers plus de pilotage, plus de transparence et moins d’angle mort entre IT et reporting.
Cette logique prend tout son sens quand on regarde les outils concrets, car c’est là que les écarts entre discours et action deviennent visibles.
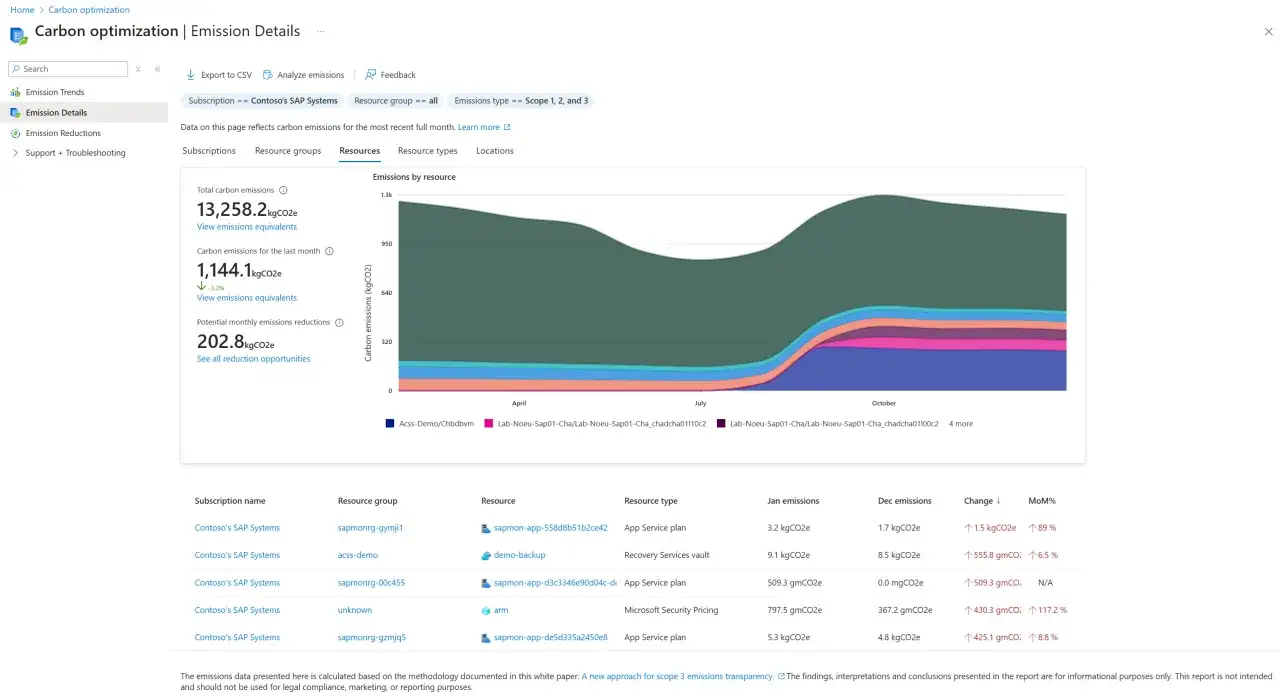
Les outils Microsoft qui rendent l’empreinte visible
Si je devais choisir un point de départ simple, je distinguerais trois niveaux: optimiser, reporter, gouverner. L’erreur classique consiste à prendre un outil de reporting pour un outil d’action, ou l’inverse.| Besoin | Outil Microsoft | Ce qu’il apporte | Point de vigilance |
|---|---|---|---|
| Optimiser Azure au niveau technique | Carbon optimization in Azure | Données d’émissions pour toutes les ressources Azure, recommandations pour changer de SKU ou arrêter des ressources sous-utilisées, données mensuelles, disponible sans coût | Vue centrée sur Azure; l’historique est limité à 12 mois dans l’interface et les données arrivent avec un léger décalage |
| Reporter au niveau de l’organisation | Emissions Impact Dashboard | Vue agrégée avec drill-down par mois, service et région, utile pour le pilotage et la communication interne | La version Azure Power BI sera retirée le 31 mars 2027; exportez l’historique et comptez une licence Power BI Pro |
| Gérer une démarche ESG plus large | Microsoft Sustainability Manager | Couverture plus large des émissions, de l’eau, des déchets et de la supply chain | Moins granulaire pour le tuning opérationnel qu’un outil Azure dédié |
Le point utile, c’est que ces outils ne se remplacent pas complètement: ils se complètent. Si je cherche à agir, je pars de Carbon optimization; si je dois aligner un reporting plus large, je passe par Microsoft Sustainability Manager; si j’ai encore des tableaux historiques sur le dashboard Power BI, j’exporte sans attendre.
Un détail pratique compte aussi: Carbon optimization met à jour ses données chaque mois, avec le mois précédent disponible autour du 19 du mois courant. Ce genre de délai est normal dans un vrai dispositif de mesure, mais il faut le connaître pour éviter les faux diagnostics.
C’est une bonne base de pilotage, mais l’impact réel se joue ensuite dans la façon de concevoir et d’exploiter les workloads.
Les leviers techniques qui font vraiment baisser l’empreinte
Réduire le surprovisionnement
Le premier gain vient presque toujours de là. Je commence par identifier les ressources qui tournent trop fort pour la charge réelle: VM surdimensionnées, bases trop grosses, clusters qui restent allumés par défaut, environnements de préproduction laissés en service. Dans Azure, Carbon optimization pointe précisément des pistes comme le changement de SKU ou l’arrêt de ressources inactives.
Sur AKS, le bon réflexe est similaire: je privilégie le scaling indépendant des composants, le stateless quand c’est possible, l’autoscaling et l’arrêt des node pools hors horaires utiles. Si une équipe me dit qu’elle “n’a rien à optimiser”, je demande d’abord la photo d’utilisation réelle sur 30 jours.
Limiter les mouvements de données et le bruit opérationnel
Le deuxième levier est moins visible mais souvent décisif. Des transferts inter-régions, une journalisation trop verbeuse, des copies multiples et une rétention sans règle claire peuvent dégrader l’empreinte autant que la consommation de calcul. Microsoft rappelle qu’une architecture peut être apparemment rentable tout en restant inefficace si elle génère trop de télémétrie, des flux inutiles ou des patterns de résilience excessifs.
Je recommande de traiter les logs comme un produit: une durée de conservation, un niveau de détail, un propriétaire et une raison d’être. Si personne ne sait pourquoi un flux est conservé pendant des mois, c’est souvent qu’il ne sert plus vraiment.
Lire aussi : Windows LAPS et Intune - Sécurisez vos comptes locaux
Rendre l’exécution carbon-aware quand le contexte le permet
Le principe est simple: faire davantage quand l’électricité est plus propre, et moins quand elle l’est moins. En pratique, cela s’applique surtout aux traitements batch, aux réentraînements IA, aux rapports planifiés ou aux tâches différables. Pour des transactions en temps réel, je ne forcerais pas ce modèle; la latence métier reste prioritaire.
Le bon arbitrage consiste donc à réserver cette logique aux charges qui acceptent un peu de flexibilité. C’est là qu’on gagne sans dégrader l’expérience utilisateur, et c’est aussi là que la stratégie devient crédible au lieu d’être théorique.
Une fois ces trois leviers en place, la question n’est plus technique seulement; elle devient organisationnelle: qui mesure, qui arbitre, et à quel rythme on corrige ?
La méthode que j’appliquerais dans une équipe française
Dans une équipe française, je rattache le sujet au duo FinOps + soutenabilité. Le premier évite le gaspillage budgétaire, le second évite de déplacer le problème vers l’empreinte carbone; dans la pratique, les deux se nourrissent souvent.
- Je fixe une base de référence par abonnement Azure, région et type de ressource.
- Je sépare production, test, sauvegarde et archive pour repérer les dérives rapides.
- Je choisis trois actions à fort impact: arrêt des ressources inutiles, right-sizing et réduction des données déplacées.
- Je donne un propriétaire à chaque action, sinon rien ne dure plus de deux sprints.
- Je raccorde l’équipe cloud, la finance IT et la fonction ESG/RSE pour éviter les doubles lectures.
- J’exporte l’historique quand un outil va être retiré, au lieu d’attendre la dernière minute.
Je suis aussi attentif à ne pas mélanger les périmètres de reporting: Azure, Microsoft 365 et les autres domaines doivent rester séparés tant que les méthodes de calcul ne sont pas homogènes. Sinon, on obtient vite des chiffres rassurants mais peu exploitables.
Avec cette discipline, le sujet cesse d’être un projet annexe et devient un réflexe de run.
Ce que je retiens pour avancer sans transformer le sujet en slogan
Si je devais résumer la logique en une phrase, je dirais ceci: la sobriété cloud se gagne par la mesure, puis par la suppression méthodique du superflu. Les bonnes plateformes ne sont pas celles qui promettent le plus, mais celles qui permettent de prouver ce qu’elles ont vraiment réduit.
- Commencez par l’outil qui vous donne une vue exploitable sur Azure, pas par un grand chantier de communication.
- Si vous utilisez encore le tableau de bord Power BI pour Azure, exportez vos données historiques avant le 31 mars 2027.
- Gardez un œil sur les workloads à forte variabilité: ce sont souvent les plus simples à améliorer et les plus rentables à optimiser.
- Ne séparez pas la lecture carbone de la lecture opérationnelle: si une optimisation dégrade trop la fiabilité, elle ne tiendra pas.
Au fond, le vrai progrès ressemble à une série de petites corrections bien suivies. C’est moins spectaculaire qu’un slogan, mais nettement plus utile pour une équipe qui veut réduire son empreinte sans perdre en performance, en maîtrise ni en lisibilité.