
La VM Azure reste, pour beaucoup d’équipes, le moyen le plus direct d’obtenir un serveur cloud vraiment maîtrisable. On choisit le système, la taille, le réseau et le disque, ce qui en fait une solution solide pour migrer une application existante, isoler un environnement de test ou héberger un service qui demande des réglages précis. Le piège, en revanche, est de la traiter comme une simple case à cocher: une machine bien choisie est efficace; une machine mal dimensionnée coûte cher et se comporte mal.
Les points à retenir avant de lancer une machine virtuelle Azure
- Une VM convient surtout quand il faut un système complet, avec un contrôle fin sur l’OS, les disques et le réseau.
- Le coût dépend d’abord de la taille, du système d’exploitation et du stockage, qui sont facturés séparément.
- Le bon dimensionnement se lit en fonction du CPU, de la mémoire, du disque et du profil réel de charge.
- Un arrêt n’est pas toujours une désallocation: pour couper le calcul, il faut vérifier l’état exact de la VM.
- Les VMs Spot peuvent être intéressantes pour des tâches tolérantes à l’interruption, mais pas pour un service critique.
- La surveillance avec Azure Monitor change vite la qualité d’exploitation, surtout quand plusieurs VM sont en jeu.
À quoi sert réellement une machine virtuelle Azure
Je la vois avant tout comme un serveur complet à la demande. On n’achète pas une application “prête à l’emploi” comme avec certains services PaaS; on récupère un système où l’on installe ce que l’on veut, avec le niveau de contrôle que l’on attend d’un serveur classique. C’est précisément ce qui la rend utile pour des logiciels hérités, des outils métiers un peu particuliers, des bases de données à contraintes spécifiques ou des environnements de développement qui doivent reproduire fidèlement la production.
Dans la pratique, une VM a du sens quand vous avez besoin d’un OS entier, d’un accès administrateur, de bibliothèques personnalisées ou d’un comportement très proche d’un serveur physique. Elle est aussi pertinente pour des migrations “lift and shift”, quand l’objectif est de déplacer rapidement une charge existante vers le cloud sans tout réécrire. En revanche, si l’application est très simple, très stateless ou déjà pensée pour être découpée en microservices, un service managé ou des conteneurs peuvent être plus sobres à exploiter.
Je retiens une règle simple: si vous voulez surtout contrôler, la VM est souvent la bonne brique; si vous voulez surtout déléguer, elle n’est peut-être pas la plus légère. Une fois ce rôle clarifié, le vrai sujet devient la taille, parce que c’est là que se joue le rapport entre confort et facture.
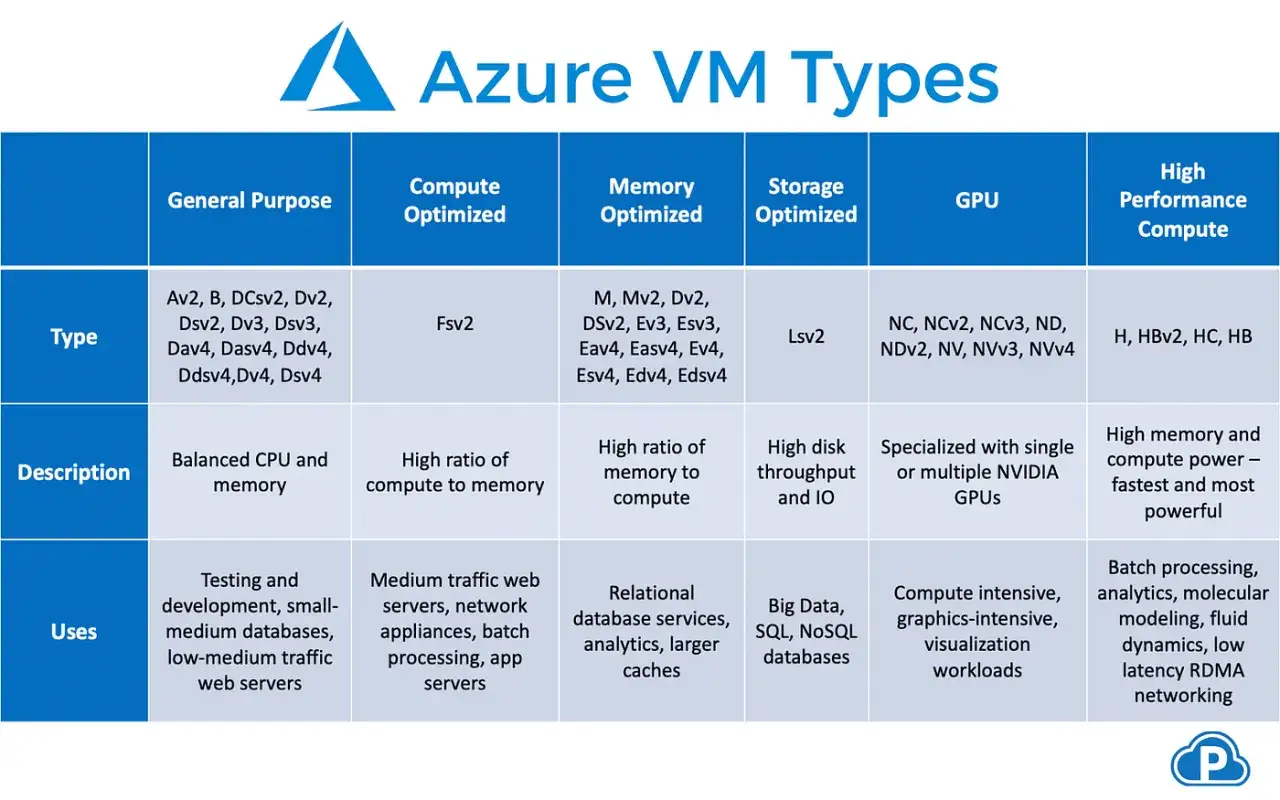
Choisir la bonne taille sans surpayer
Le nom d’une taille de VM n’est pas décoratif: il dit beaucoup sur le profil de la machine. Famille, nombre de vCPU, mémoire, accélération GPU ou orientation stockage, tout cela influence le comportement réel. J’évite donc de choisir “au feeling” et je pars toujours de la charge: est-ce que le goulot sera le CPU, la RAM, le disque ou le réseau?
| Famille | Usage typique | Ce qu’elle apporte | Quand je l’éviterais |
|---|---|---|---|
| Généraliste | Sites web, serveurs applicatifs, dev/test | Bon équilibre entre CPU et mémoire | Charges très gourmandes en calcul ou en RAM |
| Optimisée calcul | Batch, compilation, traitement intensif | Plus de puissance CPU par euro dépensé | Applications qui saturent surtout la mémoire |
| Optimisée mémoire | Bases de données, caches, analytics | Davantage de RAM par cœur virtuel | Petit site ou service peu exigeant |
| Optimisée stockage | Flux I/O lourds, traitements disque intensifs | Meilleure tenue des entrées/sorties | Charge classique sans pression sur le disque |
| GPU | IA, rendu, calcul spécialisé | Accélération matérielle dédiée | Usages génériques, car le surcoût est réel |
Je surveille aussi trois points que l’on sous-estime souvent: les vCPU (cœurs virtuels), la mémoire vive et le débit réseau. Une VM trop petite commence à “respirer court” très vite: latence qui monte, CPU collé au plafond, swap si la RAM manque. À l’inverse, une VM trop grande devient une facture de confort, utile seulement pour masquer un manque de mesure.
Il faut ajouter un détail très concret: les quotas et la capacité sont deux choses différentes. Même si votre abonnement autorise le déploiement, la région peut manquer de capacité au moment où vous créez ou redimensionnez la VM. Microsoft Learn rappelle aussi qu’un abonnement a des limites par défaut, et qu’un plafond de 20 cœurs VM par région peut bloquer des projets si l’on ne le voit pas venir. C’est exactement le genre de surprise que j’anticipe avant de cliquer sur “Créer”.
Une fois la taille stabilisée, la configuration initiale évite les erreurs qui coûtent ensuite du temps et de l’argent.
Créer et configurer la VM sans pièges inutiles
Quand je déploie une machine virtuelle, je commence presque toujours par la même logique: région, image, taille, disque, réseau, puis seulement administration. Cet ordre paraît banal, mais il évite de construire une VM techniquement correcte et opérationnellement mauvaise. Pour un public français, je privilégie en général une région européenne proche des utilisateurs ou des données, sauf contrainte réglementaire ou architecture déjà figée.
Je fais ensuite attention à l’image de départ. Windows et Linux ne posent pas les mêmes exigences d’exploitation, ni les mêmes habitudes d’administration. Une image standard bien choisie vaut mieux qu’un empilement de choix improvisés. C’est aussi à ce moment qu’il faut décider comment on se connecte: accès direct, clé SSH, compte administrateur restreint, ou chaîne d’accès plus verrouillée si la VM expose des services sensibles.
Deux erreurs reviennent souvent. La première consiste à démarrer une VM sans balises de gestion, ce qui complique le suivi des environnements, des coûts et des responsabilités. La seconde consiste à croire qu’un simple arrêt suffit à stopper la facture. En réalité, il faut distinguer l’état stopped de l’état deallocated : si la VM est seulement arrêtée mais pas désallouée, le calcul peut rester facturé. Microsoft Learn rappelle que la désallocation coupe les ressources de calcul, alors que le stockage continue de vivre sa propre vie.
Mon conseil est brutalement pragmatique: si vous n’avez pas besoin d’une VM à un instant donné, vérifiez qu’elle est bien désallouée, pas seulement éteinte. Ensuite, tout ce qui ressemble à du “bonus” doit être traité comme un coût réel, y compris les disques supplémentaires, l’IP publique, les journaux et les sauvegardes. C’est à ce stade que la sécurité et le stockage deviennent décisifs.
Sécuriser réseau, accès et disque dès le départ
Je pars toujours du principe qu’une VM exposée sans discipline de réseau finit tôt ou tard par poser problème. Le minimum consiste à n’ouvrir que les ports utiles, à limiter les sources autorisées et à garder les accès d’administration hors du périmètre public quand c’est possible. Le groupe de sécurité réseau joue ici le rôle de filtre; en clair, il définit qui peut parler à la machine et sur quels ports.
Pour l’accès, j’évite les raccourcis. Ouvrir RDP ou SSH à tout Internet pour “aller vite” reste une mauvaise habitude, surtout en environnement de production. Quand le contexte le permet, je préfère une solution d’accès intermédiaire, ou au moins un périmètre réseau strict. Le gain n’est pas seulement sécuritaire: on réduit aussi la surface de support et les risques d’erreur humaine.
Côté stockage, j’utilise presque toujours des disques managés. Azure s’occupe alors de la gestion du stockage en arrière-plan, ce qui simplifie beaucoup la vie et évite d’atteindre certaines limites d’anciens comptes de stockage. Je choisis le niveau de disque selon l’usage réel: Standard pour beaucoup de scénarios classiques, Premium quand l’I/O devient sensible. Un disque trop rapide payé pour rien est aussi inutile qu’un disque trop lent pour une base de données active.
J’essaie aussi de séparer les responsabilités: système d’un côté, données de l’autre, surtout si l’application commence à grossir. Cette séparation facilite les sauvegardes, les restaurations et les changements de taille. Quand cette base est propre, on peut enfin parler de disponibilité et de montée en charge sans bricolage.
Disponibilité, montée en charge et VMs Spot
Si la charge est importante ou si une panne unique n’est pas acceptable, il faut penser au-delà de la VM isolée. Azure propose plusieurs approches: les availability zones, les availability sets et les scale sets. Une zone de disponibilité est une séparation physique à l’intérieur d’une région; il y en a trois dans les régions qui les supportent, avec des sources d’alimentation, de réseau et de refroidissement distinctes. C’est le bon niveau de protection quand je veux éviter qu’un incident de centre de données n’abatte tout un service.
Les availability sets, eux, restent une approche logique, très utile pour répartir plusieurs machines sur une même région. Microsoft recommande au moins deux VM dans cet ensemble pour viser un niveau de service élevé, et l’intérêt est évident: si une machine tombe, l’autre prend le relais. Les scale sets vont plus loin, puisque le nombre d’instances peut augmenter ou diminuer automatiquement selon la demande. Il n’y a pas de coût pour le scale set lui-même; on paie les instances, ce qui le rend intéressant dès qu’on veut industrialiser plusieurs machines identiques.
| Option | Ce qu’elle apporte | Le revers de la médaille | Quand je la retiens |
|---|---|---|---|
| VM unique | Simplicité, faible complexité opérationnelle | Point de défaillance unique | Tests, lab, petit service non critique |
| Availability set | Répartition logique de plusieurs VM | Demande plus d’instances à administrer | Applications classiques qui doivent rester disponibles |
| Scale set | Auto-augmentation et gestion centralisée | Nécessite une architecture adaptée | Services web, backends, charges variables |
| Spot VM | Tarif variable potentiellement très attractif | Aucune garantie de maintien, éviction possible | Batch, rendu, CI, traitements tolérants à l’interruption |
Les VMs Spot méritent une approche franche: elles sont rentables pour les tâches interrompables, pas pour un service où la disponibilité est contractuelle. Leur prix varie selon la région et le SKU, on peut fixer un prix maximal, et elles peuvent être évincées à tout moment. Autrement dit, si vous avez besoin d’une capacité immédiatement fiable, je choisis plutôt une VM standard. C’est une différence de philosophie, pas seulement de tarif.
Une fois l’architecture choisie, le plus important devient le suivi dans le temps: performance, alertes, coûts et dérives éventuelles. C’est là que beaucoup de projets perdent leur discipline.
Surveiller les performances et garder le coût sous contrôle
Je considère Azure Monitor comme une pièce de base, pas comme un luxe d’équipe mature. Il donne une vision de la santé, de la performance et de la disponibilité de la VM, avec des métriques hôtes collectées automatiquement. Microsoft Learn précise que les métriques hôtes arrivent sans coût supplémentaire, alors que les métriques invitées et certains journaux demandent une configuration dédiée et peuvent générer des frais d’ingestion et de stockage. Cette distinction change vite la manière de surveiller une flotte de machines.
Dans la pratique, je regarde d’abord ce qui indique une vraie tension: CPU, mémoire, I/O disque et trafic réseau. Si la VM passe son temps à faible charge, je réduis souvent la taille plutôt que de “garder de la marge” par réflexe. Si elle monte régulièrement trop haut, j’augmente ou je répartis la charge. L’idée n’est pas d’optimiser à la marge, mais d’éviter qu’une machine serve de cache-misère permanent.
Sur le plan budgétaire, je garde trois leviers en tête. Le premier est le modèle à l’usage, utile quand la charge varie beaucoup. Le deuxième est l’option Spot, réservée aux traitements qui tolèrent une interruption. Le troisième concerne les engagements de coût pour des charges stables, en sachant que ces mécanismes visent surtout le compute et ne gomment pas automatiquement le stockage ou le réseau. Là encore, Microsoft Learn insiste sur ce point: calcul et stockage ne suivent pas la même logique de facturation.
Je rappelle aussi une règle très concrète: un arrêt “simple” ne suffit pas toujours à faire cesser la dépense. Pour stopper la facturation de calcul, il faut désallouer la VM; sinon, certaines ressources restent mobilisées. C’est l’une des causes les plus fréquentes de mauvaise surprise sur la facture, avec les disques oubliés et les journaux trop bavards. Quand tout cela est cadré, on peut passer à la dernière vérification avant mise en production.
Le contrôle final que je fais avant de passer en production
Avant de livrer une VM en production, je passe toujours par une vérification courte mais stricte. Je confirme d’abord que la région, la taille et le quota sont cohérents avec la charge prévue. J’ouvre ensuite uniquement les ports nécessaires, je vérifie le disque choisi et je m’assure que les sauvegardes, les alertes et le suivi des journaux sont bien en place. Si la VM doit rester longtemps active, je regarde aussi si un modèle de coût plus stable a du sens; si elle est temporaire, je préfère garder de la souplesse.
- La région correspond au besoin de latence ou de conformité.
- La taille est alignée sur les vrais besoins CPU, mémoire et I/O.
- Le réseau n’expose aucun port inutile.
- Le statut d’arrêt et de désallocation est compris par l’équipe.
- Le monitoring alerte sur les dérives avant qu’elles ne deviennent coûteuses.
Si je devais résumer ma méthode, je dirais qu’une bonne machine virtuelle Azure se construit moins avec des options spectaculaires qu’avec une suite de choix sobres et cohérents. Je préfère une VM mesurée, sécurisée et surveillée dès le départ à une machine trop ambitieuse qu’on découvre trop tard. C’est cette discipline qui transforme un simple serveur cloud en vraie base fiable pour un projet durable.