Azure Event Grid sert à relier des sources d’événements et des consommateurs sans alourdir l’architecture avec du polling, des scripts intermédiaires ou des bricolages de supervision. Je le considère comme une brique de routage managée, très utile dès qu’une application doit réagir vite à un changement d’état dans Azure, dans un SaaS ou dans un système métier. Dans cet article, je vais clarifier son rôle réel, expliquer comment il distribue les événements, comparer ses usages avec d’autres services Azure, et montrer les points qui comptent vraiment avant de le mettre en production.
Les points à retenir avant de le choisir
- Le service sert surtout à router des événements, pas à stocker durablement des messages ni à orchestrer des processus complexes.
- Il fonctionne très bien pour des réactions en temps réel, des automatisations et des intégrations entre services Azure.
- Le filtrage en amont évite d’envoyer des événements inutiles aux consommateurs.
- La livraison est pensée en au moins une fois, donc il faut concevoir les traitements pour supporter les doublons.
- La facturation dépend du volume d’opérations, avec 100 000 opérations gratuites par mois sur l’offre de base selon la page de tarification Microsoft.
- Le bon choix entre Event Grid, Service Bus et Event Hubs dépend surtout du besoin de notification, de file d’attente ou de streaming.
Ce que le service résout vraiment dans Azure
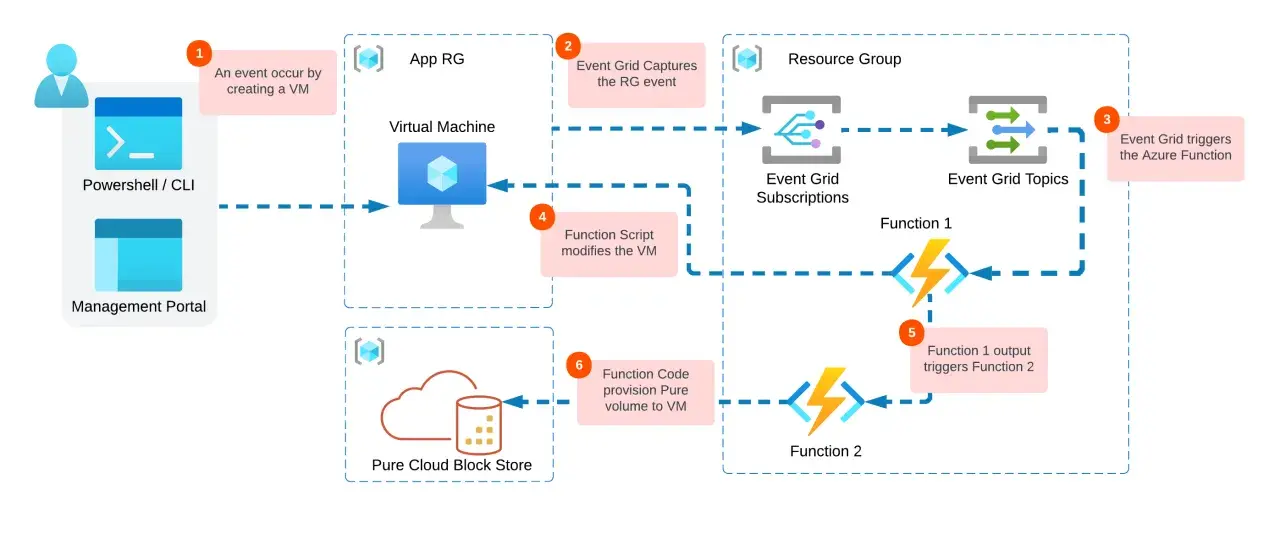
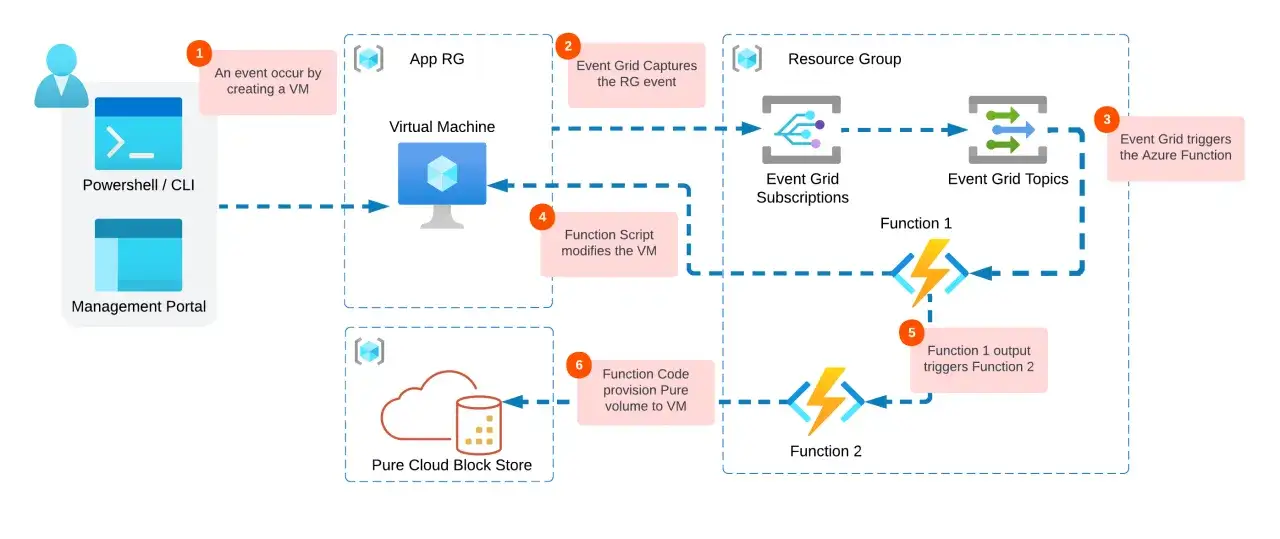
Je vois Event Grid comme une couche de distribution d’événements, pas comme un moteur métier. Son travail consiste à prendre un événement publié par une source, à évaluer les règles de subscription, puis à l’acheminer vers le bon handler avec un minimum de friction. C’est ce qui le rend très pertinent pour des scénarios où une action doit partir immédiatement après une modification dans Azure Storage, Azure Functions, un service applicatif ou une application SaaS.
Pour l’expliquer simplement, il y a trois objets à garder en tête :
- Le topic : le point d’entrée où l’on publie les événements.
- La subscription : la règle qui décide quels événements partent vers quelle destination.
- Le handler : la cible finale, par exemple une fonction, un webhook, une file ou un service Azure.
Cette logique paraît élémentaire, mais elle change beaucoup de choses en pratique. On évite le polling, on réduit le code d’infrastructure, et on rend le système plus réactif. C’est précisément pour cela qu’Event Grid prend tout son sens quand on veut une architecture pilotée par les événements plutôt qu’un enchaînement de traitements planifiés. Une fois ce rôle posé, il devient plus facile de comprendre comment les événements circulent réellement.
Comment un événement circule du producteur jusqu’au destinataire
Le parcours d’un événement est assez court, mais chaque étape compte. Une source publie un événement vers un topic, la subscription applique ses filtres, puis le service transmet l’événement au handler choisi. Dans le modèle de push, le destinataire reçoit l’information dès qu’elle est disponible; dans le modèle de pull, les consommateurs viennent la lire à leur rythme à partir d’un namespace.
La publication
La source émet une notification dès qu’un fait intéressant se produit: ajout d’un fichier, création d’une ressource, changement d’état d’un abonnement, ou événement applicatif personnalisé. Ce point est important, car Event Grid transporte des notifications et non de gros flux de données. Si le contenu métier est volumineux, je préfère publier une référence et laisser le consommateur aller chercher le reste ailleurs.
Le filtrage
Le filtrage est l’une des vraies forces du service. On peut limiter la distribution selon le type d’événement, le sujet, ou des attributs plus avancés. Microsoft Learn précise que le filtrage peut s’appuyer sur le type d’événement, le début ou la fin du sujet, ainsi que sur des champs détaillés. En pratique, c’est ce qui évite d’inonder des fonctions ou des webhooks avec des événements qui ne les concernent pas.
La livraison
Selon le handler, la livraison peut prendre plusieurs formes, mais le principe reste le même: transmettre l’événement de façon fiable vers une destination connue. Pour les flux HTTP, le service attend une réponse valide du destinataire; pour certains handlers Azure, il s’appuie sur l’identité managée et les autorisations adéquates. C’est cette mécanique qui permet d’intégrer très proprement des fonctions serverless, des files, des bus ou des endpoints métier.
Les réessais et la reprise
La fiabilité ne repose pas sur une seule tentative. La livraison est pensée en “au moins une fois”, ce qui veut dire qu’un même événement peut arriver plusieurs fois si le destinataire ne confirme pas correctement sa réception. Je trouve ce point crucial, parce qu’il impose une discipline côté application: idempotence, journalisation propre et gestion explicite des doublons. C’est le prix à payer pour un système réactif et durable.
Une fois ce chemin compris, la vraie question devient: quel service Azure correspond le mieux au besoin métier réel, et pas seulement à l’idée que l’on se fait d’un “événement”.
Quand le choisir plutôt que Service Bus ou Event Hubs
Je conseille de comparer ces services à partir du problème à résoudre, pas à partir du vocabulaire. Event Grid est excellent pour déclencher des réactions. Service Bus est plus naturel quand on veut fiabiliser des échanges de messages entre composants avec une logique de file ou de file d’attente asynchrone. Event Hubs, lui, est pensé pour absorber du streaming à grand volume et des pipelines de collecte.
| Service | Quand je le choisis | Ce qu’il fait particulièrement bien | Limite principale |
|---|---|---|---|
| Event Grid | Quand je veux déclencher une action à partir d’un événement | Routage en temps réel, filtrage, intégration Azure et SaaS | Ce n’est pas une file de traitement ni un moteur de replay |
| Service Bus | Quand je veux découpler des composants avec des messages à consommer | Files, topics, commandes asynchrones, scénarios plus transactionnels | Moins adapté au pur “event notification” que Event Grid |
| Event Hubs | Quand je dois ingérer et traiter de gros volumes de données en continu | Streaming, télémétrie, analytics, forte montée en charge | Ce n’est pas l’outil le plus direct pour déclencher des automatisations simples |
Mon réflexe est assez simple: si le besoin ressemble à “quelque chose s’est passé, réagis”, je regarde Event Grid. Si le besoin ressemble à “prends ce message, traite-le plus tard, et garde une logique de file”, je pense d’abord à Service Bus. Si le besoin ressemble à “absorbe un flot continu de données”, Event Hubs devient souvent plus pertinent. Ce tri évite pas mal d’architectures trop compliquées dès le départ, mais il faut encore régler les détails de routage et de fiabilité.
Les réglages qui évitent les incidents silencieux
Ce n’est pas le choix du service qui fait la différence au quotidien, ce sont les réglages autour. Je pense ici au schéma des événements, au filtrage, à la façon de publier, et à la stratégie de reprise. Azure Event Grid supporte notamment CloudEvents, un format standard qui facilite l’interopérabilité entre services, et son schéma natif Azure reste pratique quand on reste très ancré dans l’écosystème Microsoft.
CloudEvents ou schéma Event Grid
Si je dois intégrer plusieurs environnements ou des outils qui ne parlent pas tous le même langage, je privilégie CloudEvents. Ce format a l’avantage de normaliser la structure de l’événement, ce qui simplifie les échanges entre plateformes. En revanche, quand je reste sur des services Azure et que je veux aller vite, le schéma natif du service peut être plus direct à exploiter.
Le filtrage ne doit pas être une rustine
J’ai souvent vu des équipes mettre trop peu de filtres au début, puis compenser côté code consommateur. C’est rarement une bonne idée. Plus le filtrage est précis, moins on gaspille de temps de traitement, moins on expose les handlers à du bruit, et plus on garde des flux lisibles. Le bon filtre n’est pas celui qui “marche”, c’est celui qui minimise le travail inutile sans masquer un événement utile.
La publication doit rester simple
Quand on publie vers un topic custom, il faut envoyer les événements en tableau, même s’il n’y en a qu’un seul. Ce détail paraît mineur, mais il évite des erreurs d’intégration au moment où l’on passe du test à la vraie charge. Je recommande aussi de garder des événements courts, explicites et orientés fait métier, pas des mini-dumps applicatifs qu’aucun consommateur n’a envie de décoder.
Lire aussi : SPFx - Quand l'utiliser pour SharePoint et Microsoft 365 ?
Le traitement doit rester idempotent
Comme la livraison peut être répétée, le consommateur doit savoir reconnaître qu’un événement a déjà été traité. C’est ce que j’appelle un traitement idempotent: si le même message arrive deux fois, l’application produit le même résultat final sans double effet. Ce principe est particulièrement important pour les fonctions, les mises à jour d’état et les automatisations qui déclenchent une écriture en base ou un envoi externe.
En clair, le service ne remplace pas une conception robuste; il la rend possible plus simplement. Une fois ces règles posées, la question suivante porte naturellement sur la sécurité et le réseau, deux sujets qu’on sous-estime trop souvent.
Sécurité, identité et réseau privé
Je traite Event Grid comme une brique d’infrastructure à sécuriser dès le début, pas après coup. Lorsqu’un handler est un service Azure, l’usage d’une identité managée et des rôles RBAC adaptés est généralement la voie la plus propre. Cela évite de multiplier les secrets et rend l’exploitation plus lisible dans le temps.
- Identité managée : je l’utilise quand le handler est un service Azure compatible, car elle limite la gestion de secrets.
- RBAC : je m’en sers pour donner uniquement les droits nécessaires, pas plus.
- Endpoints privés : je les active quand le flux ne doit pas traverser le réseau public.
- Webhooks : je les réserve à des cibles qui répondent proprement avec des codes HTTP cohérents.
Pour les topics custom et les domains, les endpoints privés sont particulièrement utiles si la contrainte réseau est forte. Je les conseille dans les environnements sensibles, les applications internes et les intégrations où la surface d’exposition doit rester minimale. Dans les autres cas, je garde une configuration plus simple, tant qu’elle reste suffisamment sûre et documentée. La bonne sécurité n’est pas celle qui impressionne, c’est celle qu’une équipe peut maintenir sans erreur.
Une fois la sécurité cadrée, il reste une dernière étape très concrète: mesurer le coût réel et comprendre les limites de capacité avant d’engager la production.
Coût, limites et dimensionnement en 2026
La tarification est plus simple qu’on ne l’imagine au premier regard: elle dépend surtout des opérations, pas d’un serveur à dimensionner à la main. D’après la page de tarification Microsoft, les 100 000 premières opérations par mois sont gratuites sur l’offre de base, puis la facture suit le volume consommé. C’est pratique pour des prototypes, des environnements de test ou des flux modestes, mais il faut surveiller la croissance dès que les événements deviennent fréquents.
Les limites techniques comptent autant que le prix. Sur la couche Standard, Microsoft indique des débits pouvant aller jusqu’à 40 MB/s en entrée et 80 MB/s en sortie pour les topics namespace en HTTP, avec un support MQTT pour les scénarios IoT. Le service gère aussi la rétention CloudEvents jusqu’à 7 jours dans certains modes, ce qui peut aider quand on veut une marge de reprise plus confortable.
- Pas d’ordre garanti : je ne compte jamais sur l’ordre d’arrivée pour reconstruire une logique métier.
- Doublons possibles : je prévois toujours une déduplication ou un traitement idempotent.
- Rétroactions limitées : ce service ne remplace pas une vraie stratégie de replay à long terme.
- Charge utile raisonnable : je garde les événements compacts et je laisse les données lourdes ailleurs.
- Tests de charge indispensables : les chiffres théoriques ne disent pas comment votre application réagit en cas de pics.
En pratique, je conseille de surveiller trois indicateurs dès les premiers essais: le nombre d’opérations, la taille moyenne des événements et le taux de livraison réussie. Si ces trois mesures restent stables, le service est généralement très agréable à exploiter. Si l’un d’eux dérive trop vite, le problème vient souvent de la conception des événements, pas du service lui-même.
Les vérifications que je fais avant de le mettre en production
Avant de passer en production, je fais un contrôle très simple, mais redoutablement efficace. Je vérifie d’abord que chaque événement porte un sens métier clair et une taille contenue. Je vérifie ensuite que les filtres éliminent bien le bruit, que le handler supporte les doublons, et que les erreurs partielles partent vers une destination de reprise ou de journalisation.
- Le topic choisi correspond vraiment au type d’événement publié.
- La subscription ne laisse pas passer des événements inutiles.
- Le handler répond correctement aux échecs et aux retries.
- Le traitement est idempotent là où c’est nécessaire.
- Les droits, l’identité et le réseau ont été validés avant l’ouverture au trafic réel.
- Le coût attendu reste cohérent avec le volume mensuel visé.
Si je devais résumer mon approche, je dirais ceci: Event Grid est excellent quand on veut une réponse rapide, simple à intégrer et facile à faire évoluer, à condition de respecter ses règles de jeu. Il devient moins intéressant dès qu’on lui demande de jouer le rôle d’une file, d’un bus transactionnel ou d’un moteur de streaming. C’est justement cette frontière, bien comprise dès le départ, qui permet d’en tirer un vrai bénéfice en architecture cloud.