Les entreprises ne manquent pas de données, elles manquent surtout d’un cadre pour les relier aux bons usages. Dans un SI informatique, la vraie question n’est pas seulement de stocker, mais de savoir quelles données garder, qui peut les utiliser, comment les fiabiliser et à quel moment les transformer en décision. C’est ce point d’équilibre que je vais détailler ici, avec une lecture très concrète des données et du système d’information, du flux opérationnel jusqu’à la gouvernance.
L’essentiel à retenir sur les données et le SI
- Une donnée utile n’est pas seulement disponible, elle est fiable, traçable et rattachée à un usage.
- Le problème principal n’est presque jamais le volume, mais la circulation: doublons, ruptures de synchronisation, règles floues, accès trop larges.
- La qualité des données se joue sur quelques critères simples: exactitude, complétude, fraîcheur, cohérence, unicité et traçabilité.
- La gouvernance sert à éviter le chaos sans ralentir les équipes: rôles clairs, référentiels partagés, durées de conservation, registre des traitements.
- La sécurité doit suivre les usages réels: droits minimaux, authentification forte, sauvegardes testées, journalisation et classification des données.
- En 2026, l’IA et l’analytique rendent le sujet encore plus sensible: sans données propres, les meilleurs outils produisent surtout du bruit.
Ce que recouvrent vraiment les données dans un système d’information
Je distingue toujours la donnée brute, la donnée de référence et la donnée exploitée. La première arrive du terrain, d’un formulaire, d’un outil métier ou d’une application web; la deuxième sert de socle commun; la troisième alimente un rapport, un tableau de bord ou une décision. C’est là que la notion de valeur informationnelle apparaît: une donnée isolée dit peu de choses, mais une donnée mise en contexte devient actionnable.
On parle souvent de « données » comme d’un bloc uniforme. En réalité, elles n’ont ni le même rôle ni les mêmes risques. Une commande, un client, un produit, un ticket support ou une ligne de log ne se gèrent pas de la même manière. Et c’est précisément ce qui fait la différence entre un SI qui accompagne le métier et un SI qui le ralentit.
| Type de donnée | Rôle dans le SI | Exemple concret | Risque si elle est mal gérée |
|---|---|---|---|
| Donnée transactionnelle | Enregistre une opération métier en temps réel | Commande, paiement, ticket, inscription | Facturation fausse, incohérence opérationnelle |
| Donnée de référence | Alimente les identifiants communs et stables | Client, produit, fournisseur, agence | Doublons, désynchronisation entre outils |
| Donnée analytique | Regroupe et transforme pour piloter | Chiffre d’affaires mensuel, taux de conversion | Décisions prises sur des indicateurs biaisés |
| Donnée personnelle | Identifie ou rend identifiable une personne | Nom, e-mail, adresse, identifiant RH | Risque de non-conformité et de fuite |
| Donnée non structurée | Apporte du contexte mais demande du traitement | PDF, e-mail, image, audio, document | Valeur sous-exploitée, recherche difficile |
Le point que je vois le plus souvent sous-estimé, c’est celui des données de référence. Elles sont moins visibles qu’un dashboard, mais elles conditionnent tout le reste. Quand un client existe sous trois variantes de nom, quand un produit change d’identifiant d’un outil à l’autre, ou quand un même indicateur n’a pas la même définition selon l’équipe, le SI perd immédiatement en crédibilité. Et c’est justement cette crédibilité qui permet ensuite de faire circuler les données sans friction.
Comment les données circulent du terrain jusqu’à la décision
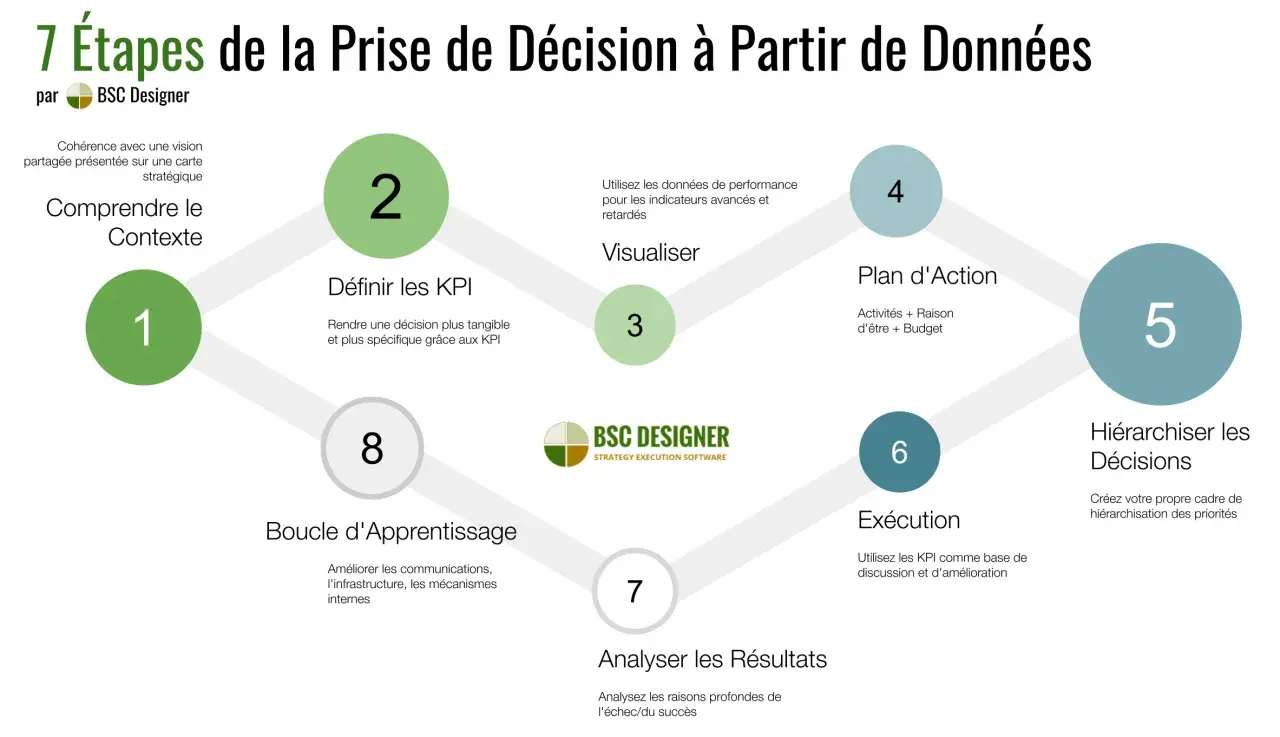
- Collecte depuis les applications métier, les formulaires, les capteurs, le web ou les outils internes.
- Contrôle pour vérifier les formats, les champs obligatoires, les doublons et les anomalies évidentes.
- Stockage dans une base opérationnelle, un entrepôt de données ou une architecture de type lakehouse selon les besoins.
- Transformation via des règles métier, des enrichissements et des consolidations, souvent automatisés.
- Restitution à travers des tableaux de bord, des API, des exports contrôlés ou des usages d’IA.
Quand cette chaîne est propre, les flux sont lisibles et les équipes savent d’où vient chaque information. Quand elle est dégradée, on voit apparaître les symptômes classiques: exports Excel en cascade, retraitements manuels, versions contradictoires d’un même chiffre, et dépendance à quelques personnes qui « savent où est la bonne donnée ». À ce stade, le problème n’est plus la donnée elle-même, mais la perte de traçabilité.
Je conseille de surveiller un concept simple mais puissant: la linéarité de la donnée, c’est-à-dire sa capacité à être suivie du point d’entrée jusqu’à l’usage final. Dès qu’on ne sait plus répondre à « d’où vient ce chiffre ? » ou « quelles transformations a-t-il subies ? », on fragilise toute la chaîne de décision. C’est aussi ce qui prépare le terrain à la section suivante: sans qualité, la circulation n’a aucune valeur durable.
Pourquoi la qualité des données change tout
La qualité ne se résume pas à « données propres » ou « données sales ». Je la regarde sur six dimensions très concrètes: l’exactitude, la complétude, la fraîcheur, la cohérence, l’unicité et la traçabilité. Si l’une d’elles manque, le résultat final peut sembler correct tout en étant trompeur. C’est particulièrement vrai pour les indicateurs de pilotage.
| Dimension | Ce qu’elle vérifie | Signal d’alerte fréquent |
|---|---|---|
| Exactitude | La donnée reflète-t-elle la réalité ? | Une adresse, un montant ou un statut erroné |
| Complétude | Les champs utiles sont-ils remplis ? | Fiches incomplètes, dossiers bloqués |
| Fraîcheur | La donnée est-elle encore à jour ? | Décision prise sur une information obsolète |
| Cohérence | Les systèmes racontent-ils la même histoire ? | Deux chiffres différents selon l’outil utilisé |
| Unicité | La même entité existe-t-elle en double ? | Un même client présent sous plusieurs fiches |
| Traçabilité | Peut-on remonter à l’origine et aux transformations ? | Impossible d’expliquer une anomalie ou un écart |
Dans un projet data, je préfère une qualité imparfaite mais mesurée à une perfection théorique que personne ne surveille. Autrement dit, il vaut mieux suivre trois règles robustes sur un périmètre critique que promettre une gouvernance globale sans exécution. Les équipes gagnent du temps quand elles savent quel champ est prioritaire, quelle source fait foi et quel seuil déclenche une correction.
Un bon réflexe consiste à définir, pour chaque donnée critique, trois éléments: la source de vérité, la règle de validation et le responsable fonctionnel. C’est simple à formuler, mais extrêmement efficace pour réduire les débats stériles. Une fois cette base posée, la gouvernance devient beaucoup plus concrète, car elle ne parle plus seulement de contrôle, mais de responsabilité partagée.
Mettre en place une gouvernance qui tient dans la durée
La gouvernance des données n’est pas un surcouche administrative; c’est ce qui empêche le SI de dériver. En France, le cadre est clair: la CNIL rappelle qu’un traitement doit avoir une finalité déterminée et une durée de conservation limitée, et Service-Public rappelle que toute entreprise qui traite des données doit respecter le RGPD. Autrement dit, on ne collecte pas « au cas où », et on ne conserve pas indéfiniment « pour être prudent ».
Sur le terrain, je recommande de clarifier cinq rôles au minimum:
| Rôle | Ce qu’il pilote | Ce qu’il évite |
|---|---|---|
| DSI | Architecture, outils, intégration, disponibilité | Empilement de solutions incompatibles |
| Métier propriétaire | Définition fonctionnelle de la donnée | Indicateurs sans sens métier |
| Data steward | Règles de qualité et suivi opérationnel | Corrections laissées au hasard |
| DPO | Conformité sur les données personnelles | Conservation excessive ou usage non cadré |
| RSSI | Protection, accès, supervision, incident | Fuite ou compromission silencieuse |
Sécuriser les données sans freiner les usages
La sécurité n’est pas seulement une affaire d’outils; c’est une manière de rendre les usages possibles sans exposer l’organisation inutilement. Je préfère une protection simple, testée et comprise à une pile complexe que personne ne sait réellement exploiter. Dans un SI moderne, l’objectif n’est pas de tout verrouiller, mais de rendre l’accès juste, mesuré et réversible.
| Risque principal | Mesure efficace | Pourquoi c’est utile |
|---|---|---|
| Compte compromis | Authentification multifacteur et moindre privilège | Réduit l’impact d’un mot de passe volé |
| Ransomware | Sauvegarde 3-2-1 et tests de restauration | Permet de repartir sans négocier avec l’attaque |
| Fuite par partage excessif | Classification des données et contrôle des droits | Évite qu’un document circule trop largement |
| Erreur humaine | Journalisation, validation et procédures simples | Permet de détecter et corriger vite |
| Interception sur le réseau | Chiffrement en transit et au repos | Protège la donnée même hors du périmètre applicatif |
Le point clé, à mon sens, est de faire coïncider le niveau de protection avec la sensibilité réelle de la donnée. Une donnée publique ne mérite pas la même politique qu’un dossier RH, une donnée client ou un référentiel financier. Quand tout est traité pareil, on protège mal ce qui compte et on complique ce qui ne l’exige pas. Une architecture saine repose donc sur quelques règles simples: segmentation, comptes nominatifs, sauvegardes vérifiées, journalisation des accès et revue régulière des habilitations.
La règle 3-2-1 pour les sauvegardes reste un bon repère: trois copies des données, sur deux supports différents, dont une copie hors site. Ce n’est pas spectaculaire, mais c’est précisément ce qui fonctionne quand il faut restaurer vite et proprement. Une fois cette base posée, le sujet n’est plus seulement la protection, mais la capacité de faire évoluer le SI sans casser son socle informationnel.
Faire évoluer un SI orienté données en 2026
Les projets data qui réussissent ne commencent pas par une plateforme, mais par une question métier bien posée. C’est encore plus vrai en 2026, où l’IA, l’automatisation et l’analytique temps réel poussent les équipes à consommer davantage de données sans toujours clarifier leur provenance. Dans un SI informatique mature, la bonne démarche consiste à relier l’outil, le modèle et l’usage, pas à empiler les briques à l’aveugle.
Si je devais résumer une feuille de route raisonnable, je la ramènerais à quatre étapes:
- Identifier les usages critiques avant de toucher à l’architecture: reporting, relation client, finance, opérationnel, conformité.
- Nettoyer les sources de vérité pour réduire les doublons et stabiliser les identifiants clés.
- Automatiser les contrôles de qualité, de fraîcheur et de cohérence afin de limiter les retours manuels.
- Documenter les responsabilités pour que chaque jeu de données ait un propriétaire, une règle et une durée de vie.
Les erreurs les plus coûteuses sont souvent les mêmes: acheter un nouvel outil avant d’avoir défini la donnée de référence, lancer une migration massive sans cartographie, ou confondre centralisation et gouvernance. Je me méfie aussi des promesses trop faciles autour de l’IA: un modèle n’améliore pas des données incohérentes, il les amplifie. Si les bases sont fragiles, la technologie accélère simplement les mauvaises décisions.
Le bon cap, ici, n’est pas la sophistication maximale. C’est un SI capable de supporter le métier, de tracer ce qu’il produit, de sécuriser ce qu’il transporte et d’évoluer sans perdre sa mémoire. Quand ce socle est en place, les équipes peuvent enfin se concentrer sur les usages au lieu de passer leur temps à débattre de la validité des chiffres.
Les signaux qui montrent qu’il faut reprendre la main sur les données
Quand je relis un SI, je cherche d’abord des symptômes très concrets. Ils disent presque toujours plus que les grands discours sur la transformation numérique:
- les équipes exportent les mêmes données dans plusieurs fichiers pour refaire les calculs à la main;
- un même indicateur change selon l’outil ou la personne qui le produit;
- les données critiques n’ont pas de propriétaire clairement identifié;
- les accès sont trop larges par facilité, puis jamais revus;
- personne ne sait vraiment combien de temps certaines données doivent être conservées;
- les corrections prennent plus de temps que la production elle-même.
Au fond, le meilleur système d’information n’est pas celui qui stocke le plus, mais celui qui transforme la bonne donnée en bonne décision, au bon moment. Si ce socle est solide, les outils suivent; s’il est fragile, aucun outil ne rattrape durablement le problème.