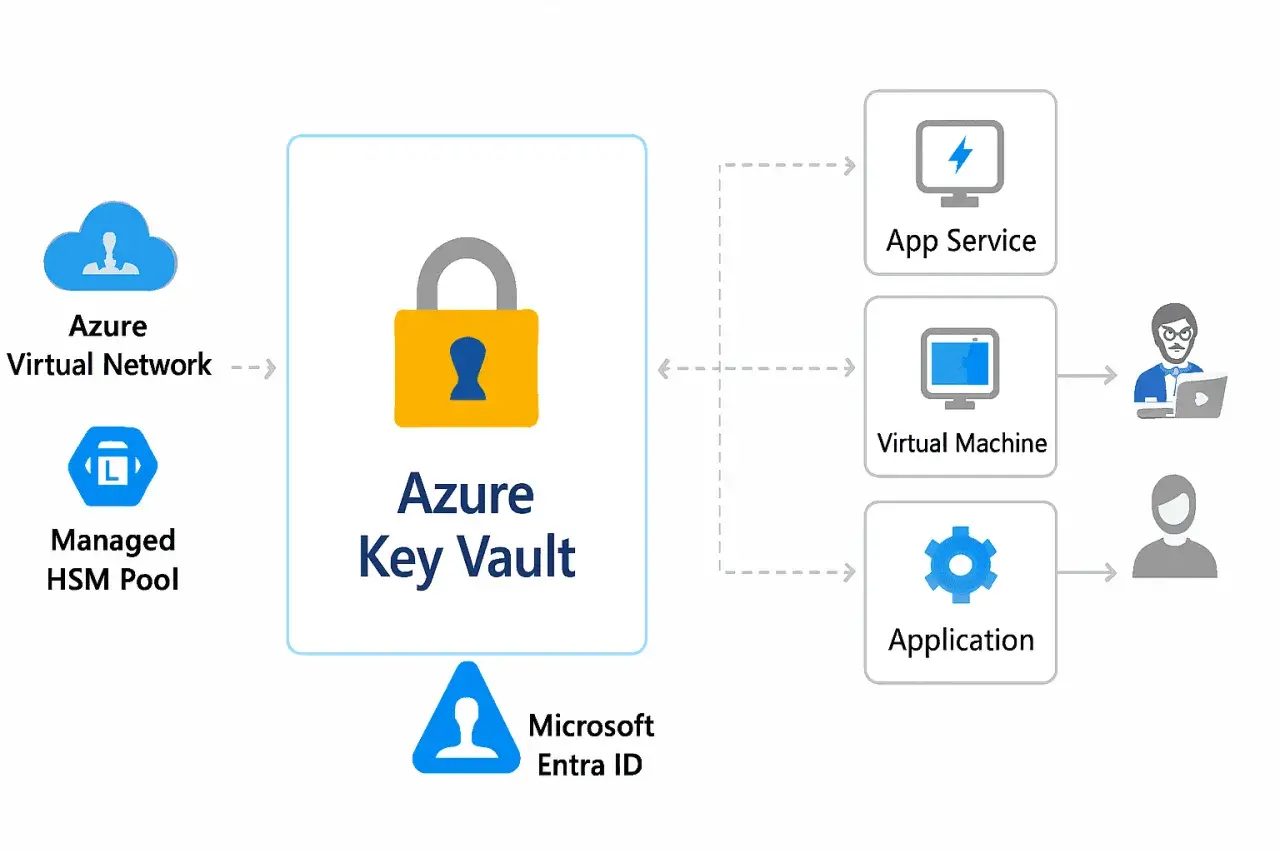
Protéger des mots de passe, des clés API, des certificats TLS ou des jetons d’accès ne se résume pas à les cacher dans une variable d’environnement. Il faut un point de contrôle central, des droits bien séparés et une stratégie de rotation qui tient la route, surtout dans un environnement Azure. Azure Key Vault répond précisément à ce besoin, à condition de l’utiliser comme un coffre de secrets et non comme un simple dépôt technique.
L’essentiel à garder en tête avant de l’adopter
- Le service sert à centraliser des secrets, des clés et des certificats, pas à stocker des données applicatives volumineuses.
- Je recommande presque toujours un coffre par application, région et environnement pour limiter l’impact d’une erreur ou d’une fuite.
- Pour les nouveaux coffres créés avec l’API 2026-02-01, Azure RBAC devient le modèle par défaut.
- En production, il faut penser réseau privé, purge protection, journalisation et rotation avant de penser fonctionnalités.
- La facture dépend surtout du nombre d’opérations et, pour les clés HSM, du nombre de clés réellement utilisées.
Ce que le service stocke vraiment et ce qu’il ne remplace pas
Je vois souvent la même confusion : un coffre de secrets n’est pas une base de données sécurisée. Il est conçu pour des objets sensibles, peu volumineux, à forte valeur, qui doivent être protégés et référencés proprement par une application. La documentation Microsoft distingue trois familles d’objets, et cette distinction est utile parce qu’elle évite beaucoup d’erreurs de conception.
| Type d’objet | Ce qu’il contient | Ce que j’en fais en pratique |
|---|---|---|
| Secrets | Mots de passe, chaînes de connexion, jetons, clés d’API | Je les garde courts, je les étiquette, je les fais tourner régulièrement |
| Clés | Clés de chiffrement, de signature ou de wrapping | Je les utilise sans exposer la matière première à l’application |
| Certificats | Certificats X.509 avec leur clé privée associée | Je privilégie l’objet certificat pour le TLS et son renouvellement automatique |
Le point important, c’est que les certificats ne devraient pas être stockés comme de simples secrets. L’objet certificat apporte une gestion du cycle de vie, un renouvellement automatisé et une versioning plus propre. À l’inverse, si je dois protéger une chaîne de connexion ou un mot de passe applicatif, le secret reste le bon format, à condition de ne pas y entasser de gros blobs de données.
Autre détail pratique souvent oublié : les objets sont versionnés. Je peux lire la dernière version, ou figer une version précise si je veux éviter un changement brutal au milieu d’un déploiement. Les noms de coffre et de pool HSM doivent être globaux et uniques, avec des contraintes de longueur, ce qui compte quand on industrialise les environnements. Une fois qu’on sait ce que l’on stocke réellement, la vraie question devient celle de l’architecture, car un bon coffre mal placé reste un mauvais choix.
Comment j’organise les coffres dans Azure
Dans les projets que je considère sérieux, je pars rarement sur un coffre partagé pour tout le monde. Je préfère un coffre par application, par région et par environnement, parce que cela réduit le rayon d’impact d’une erreur et rend l’audit beaucoup plus lisible. Dans une architecture multitenant, je pousse même l’idée plus loin avec un coffre par client quand l’isolation doit être stricte.
| Organisation | Quand je l’utilise | Pourquoi c’est pertinent |
|---|---|---|
| 1 coffre par application / région / environnement | La plupart des architectures cloud | Meilleure isolation, maintenance plus simple, incidents mieux contenus |
| 1 coffre par tenant | SaaS multiclient avec exigences d’isolement fortes | Évite qu’un client impacte les secrets d’un autre |
| 1 coffre partagé pour tout le SI | Je l’évite presque toujours | Devient vite opaque, difficile à gouverner et pénible à faire évoluer |
Je fais aussi attention aux formats de noms. Les coffres et les pools HSM ont des contraintes de longueur, et les noms d’objets aussi. Ce n’est pas un détail cosmétique : un mauvais standard de nommage crée des scripts fragiles, des imports pénibles et des erreurs de déploiement bêtes. Je conseille de prévoir une convention simple dès le départ, avec le nom de l’application, l’environnement et éventuellement la région.
Enfin, je fais le lien entre le coffre et l’identité de l’application dès le début. Si l’application peut utiliser une identité managée, je le préfère largement à une chaîne de connexion stockée ailleurs. Cette organisation n’a de valeur que si l’accès est gouverné proprement, ce qui m’amène au modèle d’autorisation.
RBAC ou policies d’accès, ce que je choisis en pratique
Le coffre fonctionne avec deux plans distincts : le plan de contrôle, qui gère la ressource elle-même, et le plan de données, qui gère les clés, secrets et certificats. C’est important, parce qu’une équipe peut avoir le droit de créer ou modifier le coffre sans avoir le droit de lire son contenu. Dans les déploiements créés avec l’API 2026-02-01, Azure RBAC devient le modèle par défaut pour les nouveaux coffres, et je trouve cette évolution plutôt saine pour la gouvernance.
| Modèle | Point fort | Limite | Mon usage |
|---|---|---|---|
| Azure RBAC | Gestion centralisée, cohérence avec le reste d’Azure, intégration avec PIM | Demande une vraie discipline de rôles et de scopes | Mon choix par défaut pour les nouveaux projets |
| Access policies | Modèle natif, simple à comprendre dans un périmètre historique | Moins homogène avec le reste de la plateforme, plus difficile à gouverner à grande échelle | Je le garde surtout pour des coffres existants en migration progressive |
Le cas où je tolère encore les access policies, c’est la migration graduelle. Si un environnement fonctionne déjà avec ce modèle et que le changement doit être maîtrisé, je l’accepte temporairement. Mais je prépare immédiatement les scripts, les templates ARM/Bicep/Terraform et les SDK pour l’API 2026-02-01, sinon la dette technique réapparaît plus vite qu’on ne le croit. Une fois les droits cadrés, il faut encore fermer les portes réseau et éviter les mauvaises habitudes de rotation.
Sécurité réseau, rotation et surveillance
Le coffre ne doit pas être seulement “bien autorisé”, il doit aussi être difficile à atteindre inutilement. Je commence donc par réduire l’exposition réseau : point d’accès privé quand c’est possible, filtrage quand il faut exposer, et architecture cohérente avec la topologie du réseau. Dans les environnements de production, je considère cela comme une base, pas comme une option avancée.
- Private endpoint quand l’application vit dans un réseau Azure maîtrisé.
- Soft delete et purge protection en production pour éviter la suppression irrécupérable.
- Diagnostic settings et alertes pour savoir qui a accédé à quoi, et quand.
- Rotation régulière des secrets, souvent sur une fenêtre de 60 à 90 jours selon la criticité.
- Deux jeux d’identifiants pour les cas où je veux tourner un secret sans interruption de service.
- Cache applicatif avec durée de vie raisonnable pour limiter les appels inutiles.
Je fais aussi attention au format des secrets. Pour des identifiants composés, je préfère une chaîne de connexion bien structurée ou un objet JSON plutôt qu’une valeur opaque impossible à maintenir. Les tags servent très bien à stocker l’échéance de rotation, le propriétaire ou le contexte d’usage. Et si la donnée devient volumineuse, je ne force pas le coffre à faire un travail de stockage qu’il n’a pas été conçu pour faire.
Pour les certificats, je reste très strict : je les gère comme des objets de certificat, pas comme des secrets déguisés. Cela apporte le renouvellement automatisé, le lien avec des autorités de certification prises en charge et une gestion plus propre du cycle de vie. Sur ce point, la rigueur évite des incidents très concrets, comme un certificat arrivé à expiration parce que personne n’avait suivi sa version active. Reste la question que beaucoup repoussent trop longtemps : le coût réel et les limites d’usage.
Combien ça coûte et où la facturation surprend
Le service n’a pas de frais de mise en service, ce qui simplifie le démarrage. En revanche, la logique de facturation mérite d’être comprise avant de brancher plusieurs applications dessus. Je raisonne toujours en deux blocs : les opérations et, si j’utilise des clés HSM, le coût lié aux clés elles-mêmes.
| Élément facturé | Comment c’est compté | Conséquence pratique |
|---|---|---|
| Opérations sur secrets, clés et certificats | Par tranche de 10 000 opérations authentifiées | Réduire les appels et mettre en cache change vraiment la facture |
| Renouvellements de certificats | Facturation séparée par renouvellement | Automatiser oui, mais en gardant un œil sur le volume |
| Clés HSM | Par clé utilisée au moins une fois dans les 30 derniers jours, plus les opérations | Les versions historiques d’une clé peuvent compter comme des clés distinctes |
Le piège classique, c’est de multiplier les lectures de secrets à chaque requête applicative. Techniquement, ça fonctionne, mais économiquement et opérationnellement, c’est maladroit. Chaque appel REST authentifié compte comme une opération, et le service peut throttler si on le sollicite trop fortement dans un même coffre ou dans une même région. J’anticipe donc avec un cache côté application, un retry avec backoff exponentiel et une stratégie de lecture qui évite les rafales inutiles.
Autre point à ne pas négliger : les clés HSM sont facturées de manière plus contraignante que les clés logicielle protégées, surtout si vous gardez beaucoup de versions ou si vous faites tourner fréquemment vos objets. Cela n’empêche pas de les utiliser, mais il faut le faire pour de bonnes raisons de sécurité ou de conformité, pas par réflexe. Si le besoin métier n’exige pas une séparation matérielle stricte, la version standard suffit souvent. Et avant de faire un choix définitif, je préfère éliminer les erreurs les plus classiques une par une.
Les erreurs qui font perdre du temps en production
Quand un coffre pose problème, ce n’est presque jamais à cause d’une seule grande faute. C’est plutôt l’accumulation de petites décisions pratiques qui finissent par fragiliser l’ensemble. Voici les erreurs que je vois le plus souvent, et que j’évite systématiquement.
- Stocker des certificats comme de simples secrets alors que l’objet certificat apporte un cycle de vie plus propre.
- Utiliser un coffre comme un espace de données alors qu’il n’est pas conçu pour contenir de gros volumes.
- Oublier la version des objets et casser un déploiement en silence après une rotation.
- Donner trop de droits par confort, puis perdre la lisibilité des accès réels.
- Reporter la migration RBAC alors que les nouveaux coffres partent déjà sur ce modèle avec l’API 2026-02-01.
- Ignorer le throttling et découvrir tardivement que l’application interroge le coffre beaucoup trop souvent.
- Négliger purge protection et sauvegarde sur les environnements critiques.
J’ajoute un point souvent sous-estimé : les noms. Un standard de nommage bancal produit des coffres difficiles à retrouver, des environnements mal alignés et des scripts fragiles. Mieux vaut un schéma simple, stable et documenté qu’une convention “intelligente” que personne ne respecte au bout de trois mois. Avec ces pièges en tête, la mise en service devient beaucoup plus prévisible.
Ce que je vérifie avant de le laisser en service
Si je devais résumer ma pratique, je dirais que je cherche d’abord la simplicité d’exploitation, puis la robustesse, puis seulement l’optimisation. Un coffre bien préparé n’est pas spectaculaire, mais il devient invisible au bon sens du terme : il protège, il journalise et il ne crée pas de dette opérationnelle supplémentaire.
- Un coffre dédié par périmètre important, pas un stockage central unique pour tout.
- Une identité managée pour l’application, avec RBAC si possible dès le départ.
- Des secrets courts, tagués et rotatifs, avec une politique claire de durée de vie.
- Des certificats gérés comme des certificats, pas comme des chaînes de texte.
- Des logs, des alertes et un endpoint privé dès que la criticité monte.
Quand ces conditions sont réunies, le coffre devient un vrai composant de sécurité et non une couche de plus à supporter. C’est cette combinaison qui me paraît la plus saine dans Azure en 2026 : peu d’exceptions, des accès lisibles, des rotations maîtrisées et une architecture qui reste compréhensible même après plusieurs mois d’exploitation.