Ce qu’il faut retenir pour piloter une application sans l’alourdir
- La maintenance corrective remet en état ce qui casse ou dysfonctionne.
- La maintenance évolutive ajoute ou améliore une fonctionnalité utile au produit.
- La frontière avec la maintenance adaptative dépend souvent de l’environnement technique, pas du besoin métier.
- Une bonne priorisation regarde l’impact utilisateur, le risque, la sécurité et le délai de mise en œuvre.
- Un correctif bien traité passe par la reproduction, l’analyse d’impact, des tests de non-régression et un suivi après déploiement.
- Sans indicateurs, on confond vite vitesse d’exécution et qualité réelle.
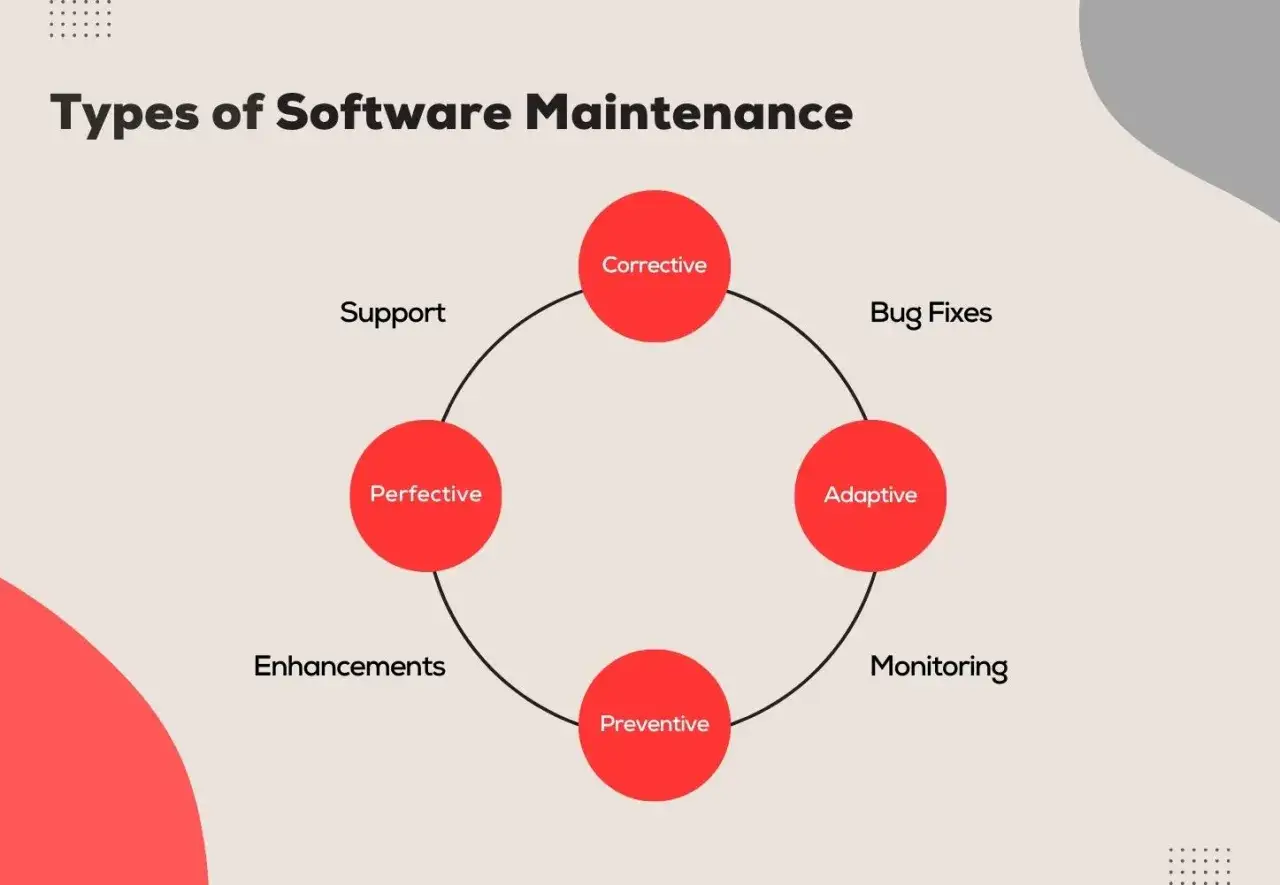
Distinguer correction, évolution et adaptation
La confusion vient souvent du vocabulaire. En pratique, je sépare toujours ce qui répare, ce qui ajoute de la valeur et ce qui assure la compatibilité avec un environnement qui a changé. Les standards de maintenance logicielle, comme l’ISO/IEC/IEEE 14764, rappellent d’ailleurs qu’une correction ne se traite pas comme une amélioration fonctionnelle ou une adaptation à une nouvelle plateforme.
Sur un site web, la différence est assez nette si on prend des cas concrets. Un bouton de panier qui ne répond plus relève du correctif. L’ajout d’un filtre de recherche, d’un export CSV ou d’un parcours d’abonnement plus fluide relève de l’évolutif. La migration d’un module vers une nouvelle version de framework, d’un moteur de base de données ou d’une API externe touche plutôt à l’adaptatif.
| Type de maintenance | Objectif | Déclencheur | Exemple web | Risque si on mélange tout |
|---|---|---|---|---|
| Corrective | Réparer un dysfonctionnement constaté | Bogue, incident, régression, faille | Formulaire de paiement qui échoue | On transforme un incident en mini-projet flou |
| Évolutive | Ajouter ou améliorer une capacité utile | Besoins métier, retours utilisateurs, stratégie produit | Ajout d’un tri par popularité | On sous-estime les tests et l’impact UX |
| Adaptative | Maintenir la compatibilité avec l’environnement | Changement de version, de dépendance, de réglementation | Mise à niveau PHP, Node ou d’une API tierce | On croit livrer une simple mise à jour alors qu’on ouvre un chantier transversal |
| Préventive | Réduire le risque futur | Dette technique, zones fragiles, obsolescence | Refactorisation ciblée, ajout de tests | On repousse sans cesse les fondations du produit |
Cette distinction n’est pas théorique. Quand une équipe appelle tout “maintenance”, elle finit par traiter avec la même urgence une panne de production, une demande de fonctionnalité et une mise à niveau technique. C’est là que le planning se dérègle. Une fois cette frontière posée, la vraie question devient : quoi faire passer en premier, et selon quels critères ?
Prioriser sans se tromper quand tout semble urgent
Je ne classe jamais les demandes uniquement à l’intuition. Une bonne priorisation part de l’impact réel : est-ce que l’utilisateur est bloqué, est-ce que le revenu est touché, est-ce que la sécurité est engagée, est-ce que le problème se répète ? Dans un contexte de TMA, cette logique doit être visible dans le contrat ou dans le backlog, sinon chaque ticket devient une négociation.
Quand je dois arbitrer, j’utilise une grille simple sur cinq axes. Cela évite de surévaluer le bruit et de sous-estimer les vrais risques.
- Impact utilisateur : un incident qui bloque l’achat, la connexion ou la publication passe devant tout le reste.
- Portée : plus le bug touche de parcours, de comptes ou de pages, plus il est prioritaire.
- Risque métier ou juridique : une erreur de prix, de consentement ou de donnée personnelle n’a pas le même poids qu’un défaut visuel.
- Récurrence : un problème qui revient souvent indique presque toujours un mauvais fondement technique ou fonctionnel.
- Effort de correction : à impact égal, je privilégie souvent le ticket qui apporte le meilleur ratio entre coût et bénéfice.
Le point délicat, c’est le délai de service. Le SLA, c’est l’engagement de prise en charge ou de résolution attendu. S’il n’est pas clair, l’équipe passe son temps à arbitrer à la main. Avec un SLA explicite, un bug critique ne se retrouve pas derrière une évolution cosmétique simplement parce qu’il a été remonté plus tard. Et c’est justement cette discipline qui permet ensuite de dérouler une intervention propre, sans improvisation.
Le déroulé d’une intervention propre
Sur le terrain, les meilleurs résultats viennent rarement d’un “fix rapide” isolé. Ils viennent d’une chaîne courte mais rigoureuse. Je préfère un correctif bien cadré à trois bricolages successifs qui rouvrent le même incident.
1. Qualifier le besoin avant d’écrire la moindre ligne
Je commence par reformuler la demande en langage métier, puis en langage technique. Est-ce un bug reproductible, une nouvelle attente fonctionnelle ou une conséquence d’environnement ? Cette étape évite les faux correctifs, surtout quand le symptôme visible masque la cause réelle.
2. Reproduire et isoler
Un défaut qu’on ne reproduit pas reste souvent mal compris. Je vérifie le contexte, les données d’entrée, la version déployée, les logs, les dépendances et les cas limites. Dans une application web, beaucoup de problèmes apparaissent seulement sur un navigateur, un compte ou un jeu de données précis.3. Mesurer l’impact du changement
Avant de coder, j’évalue ce que la modification peut casser ailleurs. C’est particulièrement vrai pour la maintenance évolutive, car une nouvelle fonctionnalité modifie presque toujours un écran, une API, un calcul ou une règle métier. Plus le périmètre est large, plus il faut penser tests de non-régression, documentation et rollback.
4. Définir des critères d’acceptation
Un ticket bien écrit décrit ce qui doit être vrai après correction ou livraison. Par exemple : “le paiement se valide sur mobile”, “le filtre reste actif après pagination” ou “la nouvelle option n’affecte pas les abonnés existants”. Ces critères font gagner du temps à toute l’équipe, y compris en recette.
Lire aussi : Architecture Applicative - Monolithe, Hexagonale ou Microservices?
5. Déployer progressivement et surveiller
Je favorise quand c’est possible les déploiements progressifs, les feature flags et les retours de monitoring. Le feature flag, c’est un interrupteur logiciel qui permet d’activer ou non une fonction sans redéployer. C’est précieux pour une évolution risquée, mais aussi pour sécuriser un correctif sensible.
Ce déroulé est simple, mais il protège l’essentiel : livrer sans perdre le contrôle. La suite logique consiste à regarder ce qui abîme le plus la qualité du produit, souvent sans bruit, à force de petites décisions mal cadrées.
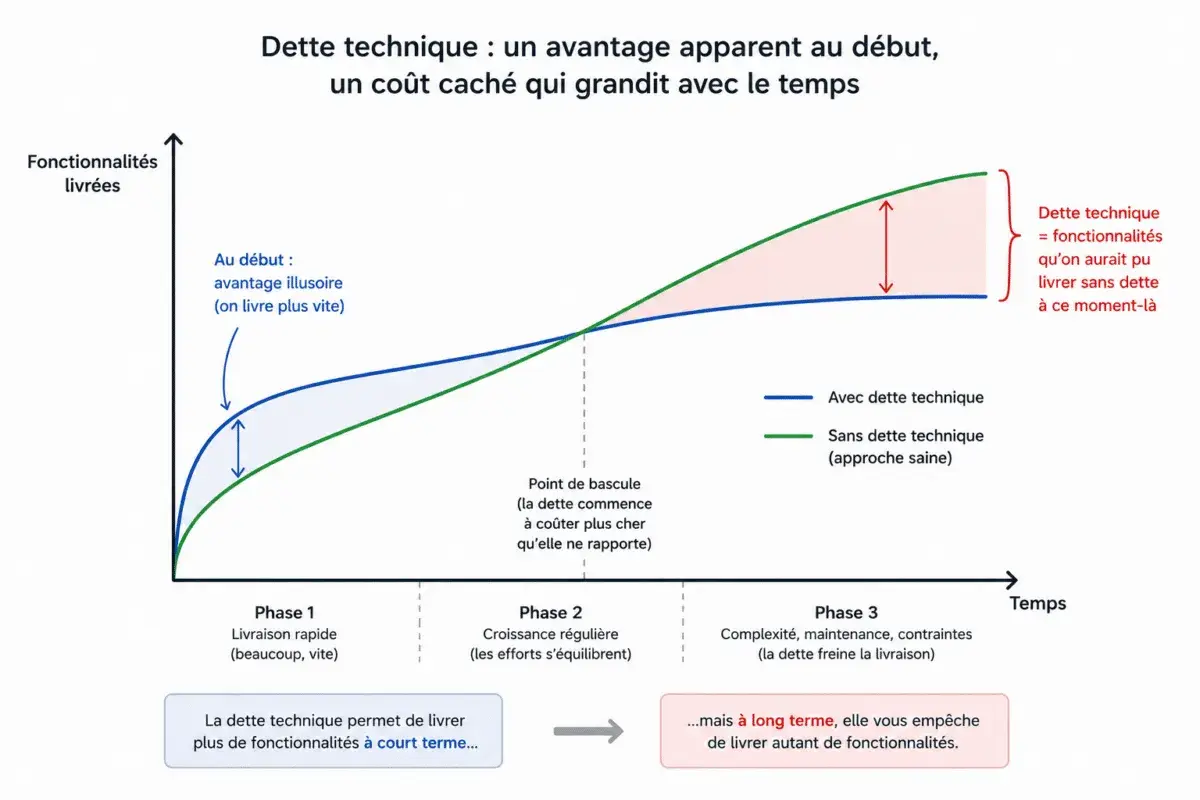
Les erreurs qui transforment une petite demande en dette technique
La dette technique n’apparaît pas seulement quand le code est “mal écrit”. Elle se crée surtout quand on accepte des raccourcis répétés. C’est la raison pour laquelle une maintenance mal gérée finit par ralentir toute l’équipe, même si les tickets semblent livrés vite.
- Corriger sans reproduire : on applique un patch à un symptôme, mais pas à la cause.
- Mélanger bugfix et nouvelle fonction : le ticket devient difficile à tester, à relire et à valider.
- Ignorer les tests de non-régression : on gagne quelques minutes et on perd souvent des heures au prochain incident.
- Modifier en urgence sans trace : un contournement invisible devient vite une règle implicite dans le code.
- Sous-documenter les changements : le prochain développeur doit redécouvrir les mêmes pièges.
- Reporter trop longtemps les refontes ciblées : un module fragile attire les incidents comme un aimant.
Je vois souvent le même mécanisme : un correctif rapide semble rentable, puis il oblige à en faire un deuxième, puis un troisième. À ce stade, ce n’est plus une économie, c’est une facture différée. Pour garder la main, il faut donc aussi suivre quelques indicateurs simples et lisibles.
Les indicateurs qui montrent si la maintenance reste saine
Je préfère peu d’indicateurs, mais bien choisis. L’objectif n’est pas de faire du reporting pour le reporting, c’est de savoir si l’équipe corrige vraiment les problèmes ou si elle les déplace dans le temps.
| Indicateur | Ce qu’il mesure | Ce qu’il faut surveiller |
|---|---|---|
| MTTR | Le temps moyen pour rétablir le service après un incident | S’il monte, la correction devient trop lente ou trop complexe |
| Taux de réouverture | La part des tickets considérés comme résolus mais qui reviennent | S’il grimpe, le problème a été traité trop superficiellement |
| Défauts échappés | Les bugs détectés après mise en production | S’il augmente, la recette ou les tests manquent de couverture |
| Lead time | Le délai entre la demande et la mise en ligne | S’il s’allonge, le backlog ou les dépendances bloquent la livraison |
| Part des tickets correctifs | La place prise par les bugs par rapport aux évolutions | S’il devient trop dominant, le produit avance moins qu’il ne répare |
Je regarde aussi le volume de hotfixes. Un hotfix, c’est un correctif expédié très vite en production pour neutraliser un incident. Il reste utile, mais s’il devient fréquent, c’est souvent le signe qu’on manque de temps pour traiter correctement les causes profondes. Une équipe saine ne cherche pas à supprimer tout correctif rapide ; elle cherche à en réduire la fréquence.
Ce que je recommande pour un produit web qui doit durer
Si je devais résumer ma pratique en une règle, ce serait celle-ci : corriger vite ce qui bloque, évoluer proprement ce qui crée de la valeur, et ne jamais laisser l’urgence décider seule. Un produit web durable n’est pas celui qui n’a pas de bugs ; c’est celui qui sait les absorber sans sacrifier sa structure ni sa capacité à livrer.
Dans une équipe de développement, je conseille de garder un backlog unique mais des règles de priorité très explicites. Les corrections critiques passent devant, les évolutions restent cadrées par des critères d’acceptation, et les chantiers adaptatifs sont traités comme de vrais sujets d’architecture, pas comme de simples mises à jour. C’est cette discipline qui permet de garder une base saine tout en faisant avancer le produit.
En pratique, je regarde toujours la même chose avant de lancer une demande : est-ce que cela répare, améliore ou sécurise le système ? Si la réponse est claire, la maintenance devient un levier de qualité. Si elle ne l’est pas, le risque est simple : on confond mouvement et progrès.