Une architecture applicative solide évite surtout deux écueils : le code qui se transforme en labyrinthe, et les évolutions qui deviennent trop coûteuses pour être livrées sereinement. Je détaille ici comment structurer une application web ou logicielle pour qu’elle reste lisible, testable et capable d’évoluer sans réécriture permanente. Vous verrez aussi quand un monolithe modulaire suffit, quand une approche hexagonale apporte un vrai gain, et à quel moment les microservices deviennent une bonne idée plutôt qu’un fardeau.
Les repères utiles pour décider sans surconcevoir
- La séparation métier/infrastructure est le vrai sujet, pas l’arborescence des dossiers.
- Le monolithe modulaire reste souvent le meilleur point de départ pour un projet web.
- L’architecture hexagonale devient intéressante quand le domaine métier mérite d’être protégé du framework et de la base de données.
- Les microservices n’améliorent pas une conception confuse ; ils l’exposent plus vite.
- L’observabilité, la sécurité et les tests doivent être pensés dès le départ, pas ajoutés après coup.
Ce qu’une architecture applicative doit vraiment garantir
Quand je conçois ou relis un projet, je cherche d’abord des garanties très concrètes : comprendre le code rapidement, tester le métier sans dépendre de l’interface, faire évoluer une fonctionnalité sans tout casser, et déployer sans transformer chaque correctif en opération risquée. Une bonne structure logicielle sert ces objectifs, pas l’inverse.
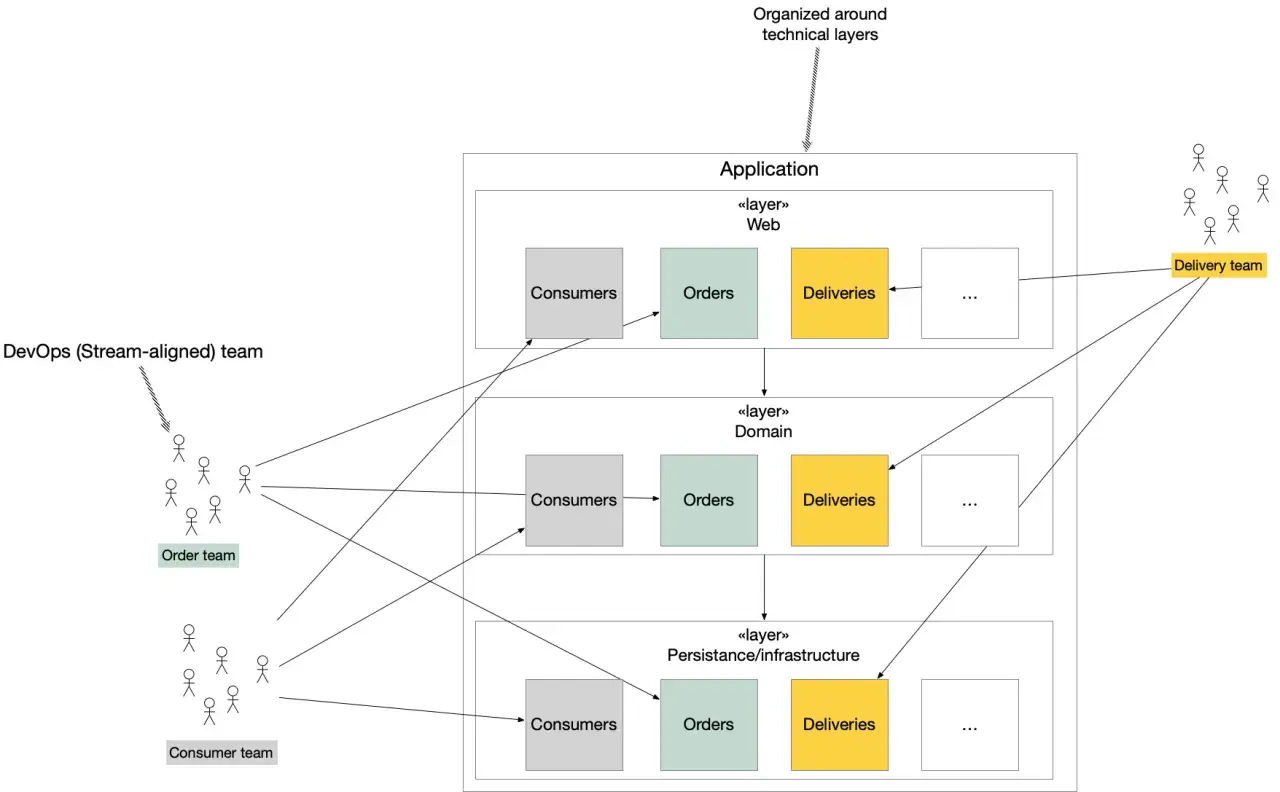
Le piège classique consiste à confondre organisation technique et organisation fonctionnelle. On peut avoir un projet très propre visuellement, avec des dossiers bien rangés, et pourtant un couplage désastreux entre les contrôleurs, la base de données et les règles métier. Dans la pratique, je regarde surtout si les responsabilités sont nettes et si les dépendances pointent dans le bon sens.
| Couche | Rôle principal | Ce qu’elle doit éviter |
|---|---|---|
| Présentation | Recevoir les requêtes, afficher les réponses, gérer la validation simple | Porter la logique métier |
| Application | Orchestrer les cas d’usage et les transactions | Parler directement à la base de données |
| Domaine | Contenir les règles métier et les invariants | Dépendre du framework ou de l’interface |
| Infrastructure | Gérer la persistance, les API externes, les files, l’email | Décider des règles fonctionnelles |
Cette séparation n’est pas une coquetterie d’architecte. Elle permet de faire vivre l’application plus longtemps avec moins de friction, ce qui devient essentiel dès que le produit prend du volume ou que l’équipe change. C’est précisément là que les modèles d’organisation prennent tout leur sens.
Les modèles d’architecture à connaître avant de trancher
Je vois souvent des équipes vouloir choisir un modèle “à la mode” alors que la vraie question est plus simple : quel niveau de complexité le projet doit-il absorber maintenant, et lequel peut-il supporter plus tard ? Tous les modèles ne servent pas les mêmes objectifs, et il faut accepter leurs compromis.
| Modèle | Quand il marche bien | Atout majeur | Limite principale |
|---|---|---|---|
| Monolithe modulaire | Produit encore mouvant, petite ou moyenne équipe | Déploiement simple, compréhension rapide | Les frontières internes doivent être disciplinées |
| Architecture en couches | Applications CRUD, SI classique, besoin de lisibilité | Très accessible pour les équipes | Peut devenir rigide si les couches se mélangent |
| Hexagonale / propre | Domaine métier dense, multiples intégrations | Tests plus simples, métier protégé | Demande plus de discipline au départ |
| Microservices | Équipes autonomes, livraisons fréquentes, forte charge | Déploiement indépendant des services | Complexité opérationnelle et débogage distribué |
Mon avis est assez net : tant que vous n’avez pas une vraie raison opérationnelle de fragmenter le système, un monolithe modulaire bien tenu est souvent la meilleure réponse. L’architecture hexagonale, elle, devient intéressante quand la logique métier mérite d’être isolée du framework, des APIs et de la persistance. Quant aux microservices, ils n’apportent de valeur que si l’organisation sait déjà gérer les coûts qui viennent avec eux : supervision, réseau, versioning et contrats entre services.
On peut aussi croiser ces modèles. Une application peut être monolithique dans son déploiement, tout en étant très propre dans son découpage interne. C’est même souvent la combinaison la plus saine au début.
Comment la concevoir pour un projet web concret
Quand je pars d’une feuille blanche, je ne commence pas par le framework. Je commence par les cas d’usage et par les frontières du métier. Une plateforme éditoriale, un back-office e-commerce ou une application musicale n’ont pas le même cœur fonctionnel, même si les briques techniques se ressemblent.
- Identifier les usages réels : créer, publier, rechercher, modérer, facturer, notifier, importer.
- Nommer les frontières du domaine : publication, catalogue, utilisateur, abonnement, paiement, notification.
- Définir les ports : API REST, GraphQL, événements, tâches asynchrones, webhooks.
- Placer la logique métier au centre : les règles doivent rester utilisables même si l’interface change.
- Isoler les dépendances externes : base de données, services tiers, stockage de fichiers, messagerie.
- Prévoir les tests au bon niveau : tests unitaires pour le domaine, tests d’intégration pour les frontières, tests de contrat pour les API.
Dans ce cadre, le terme de bounded context devient utile : c’est une frontière de sens à l’intérieur de laquelle un mot, un objet ou une règle a une signification précise. Ce n’est pas un luxe théorique, c’est une façon très concrète d’éviter qu’un même concept soit interprété différemment par plusieurs équipes ou plusieurs modules.
Pour une équipe réduite, j’insiste souvent sur un point : commencez simple, mais ne commencez pas brouillon. Il vaut mieux un monolithe propre avec des frontières claires qu’un pseudo-microservice dispersé où chaque morceau dépend du reste dans tous les sens. Si le produit grandit, la séparation sera alors beaucoup plus facile à faire évoluer.
Les erreurs qui fragilisent le plus vite un projet
Les erreurs d’architecture ne se voient pas toujours tout de suite. Elles se manifestent d’abord par des symptômes discrets : une fonctionnalité banale devient longue à coder, les tests deviennent lourds, et une correction mineure provoque des effets secondaires inattendus. J’en vois revenir cinq très souvent.
- Mettre la logique métier dans les contrôleurs : cela marche au début, puis chaque changement oblige à toucher plusieurs points d’entrée.
- Découper en microservices trop tôt : le système gagne en dispersion avant de gagner en autonomie.
- Laisser la base de données dicter le modèle métier : on obtient un projet qui suit la structure du stockage, pas celle du besoin réel.
- Mélanger accès externe et règles internes : plus rien n’est testable sans lancer tout le système.
- Confondre architecture et framework : le framework est un outil, pas la stratégie de conception.
La correction n’est pas toujours spectaculaire. Souvent, il suffit de déplacer la logique métier vers un noyau plus stable, de créer une couche d’orchestration claire, puis de faire dépendre les détails techniques de cette base. C’est moins visible qu’une réécriture, mais beaucoup plus rentable.
Je conseille aussi de surveiller les dépendances circulaires. Dès qu’un module dépend d’un autre qui dépend du premier, le projet commence à perdre sa capacité à évoluer proprement. Ce type de dette est particulièrement coûteux à rattraper une fois que la base de code a grossi.
Sécurité, performance et observabilité ne sont pas des détails
Une architecture bien pensée ne sert pas seulement à organiser le code. Elle doit aussi faciliter les sujets qui deviennent critiques dès que l’application est exposée à de vrais utilisateurs : la sécurité, la performance et la capacité à comprendre ce qui se passe en production.
Pour la sécurité, je préfère une règle simple : authentifier tôt, autoriser précisément, valider les entrées partout, et garder les secrets hors du code. Plus les frontières sont claires, plus il devient facile de savoir où s’appliquent les contrôles. Dans un système mal découpé, on finit souvent par multiplier les vérifications au hasard, ce qui donne une illusion de sécurité sans vraie maîtrise.
Sur la performance, la distinction entre composant stateless et composant stateful compte énormément. Une partie stateless se met à l’échelle et se redéploie plus facilement, parce qu’elle ne garde pas d’état local critique entre deux requêtes. Dès qu’il faut conserver une session, un panier, un workflow ou une progression utilisateur, je préfère externaliser cet état de manière explicite plutôt que de le cacher dans la mémoire du serveur.
L’observabilité, elle, est souvent sous-estimée. Dans une application distribuée, on ne peut pas se contenter de logs bruts. Il faut des métriques, des traces corrélées et des journaux exploitables pour relier une requête utilisateur à ses effets dans le système. Sans cela, le diagnostic d’un incident devient presque une enquête à l’aveugle.
- Logs structurés pour retrouver rapidement un incident.
- Métriques pour voir les tendances de charge, de latence et d’erreur.
- Tracing distribué pour suivre une requête à travers plusieurs composants.
- Seuils d’alerte pour détecter une dérive avant qu’elle ne devienne visible par les utilisateurs.
En pratique, j’évite de dissocier architecture et exploitation. Si une structure est élégante mais impossible à superviser, elle finit par coûter plus cher qu’un design un peu moins ambitieux mais maîtrisable.
Quand moderniser l’existant plutôt que repartir de zéro
La question revient souvent dans les équipes web et logiciel : faut-il réécrire, refactorer ou migrer progressivement ? Ma réponse est presque toujours la même : repartir de zéro est rarement le bon premier réflexe. Une réécriture efface aussi les connaissances, les compromis et les cas particuliers que le produit a accumulés avec le temps.
| Situation | Réponse souvent la plus saine | Pourquoi |
|---|---|---|
| Le système fonctionne mais évolue mal | Modernisation progressive | On conserve la valeur métier et on réduit le risque |
| Le domaine est clair, mais les dépendances techniques sont confuses | Re-cadrage de l’architecture interne | On sépare les responsabilités sans casser le produit |
| Une partie du système doit changer vite | Strangler pattern | On remplace morceau par morceau au lieu de tout basculer d’un coup |
| Une brique externe est trop couplée au cœur | Couche d’adaptation ou anti-corruption | On protège le domaine des formats et règles externes |
Le bon indicateur n’est pas “est-ce que ce serait plus propre si on recommençait ?”, mais “peut-on améliorer le système sans perdre sa stabilité ni sa vitesse de livraison ?”. Dans beaucoup de cas, la réponse est oui, à condition d’accepter une migration par étapes et de garder le domaine au centre des décisions.
Je recommande de viser une transition visible par le produit, pas par le dogme technique. Si les utilisateurs ne gagnent rien et que l’équipe prend un risque élevé, la réécriture totale est rarement défendable.
Les décisions qui font la différence quand le produit grandit
Si je devais résumer ce sujet en une ligne, je dirais ceci : une bonne structure logicielle n’essaie pas d’être brillante, elle essaie d’être durable. Commencez par clarifier le métier, protégez la logique centrale, puis laissez l’infrastructure et les interfaces s’adapter autour de ce noyau.
Pour avancer sans surconcevoir, je garde quatre repères simples : un domaine explicite, des dépendances orientées vers l’intérieur, des frontières testables et une exploitation observable. Ce sont ces choix-là qui font gagner du temps plus tard, bien plus que le fait d’adopter un modèle réputé à la mode.
Quand un projet grossit, la meilleure architecture n’est pas celle qui impressionne sur un schéma, mais celle qui permet à l’équipe de livrer vite, de corriger sans stress et d’évoluer sans perdre la maîtrise du système.