La santé d’une application ne se joue pas seulement au moment du lancement. Une fois en production, il faut corriger les incidents, suivre les dépendances, sécuriser les mises à jour et faire évoluer l’outil sans casser l’existant. C’est précisément le rôle de la maintenance applicative, un sujet très concret pour toute équipe web ou logiciel qui veut garder un produit fiable, rapide et utile sur la durée.
Les repères essentiels pour garder une application fiable dans la durée
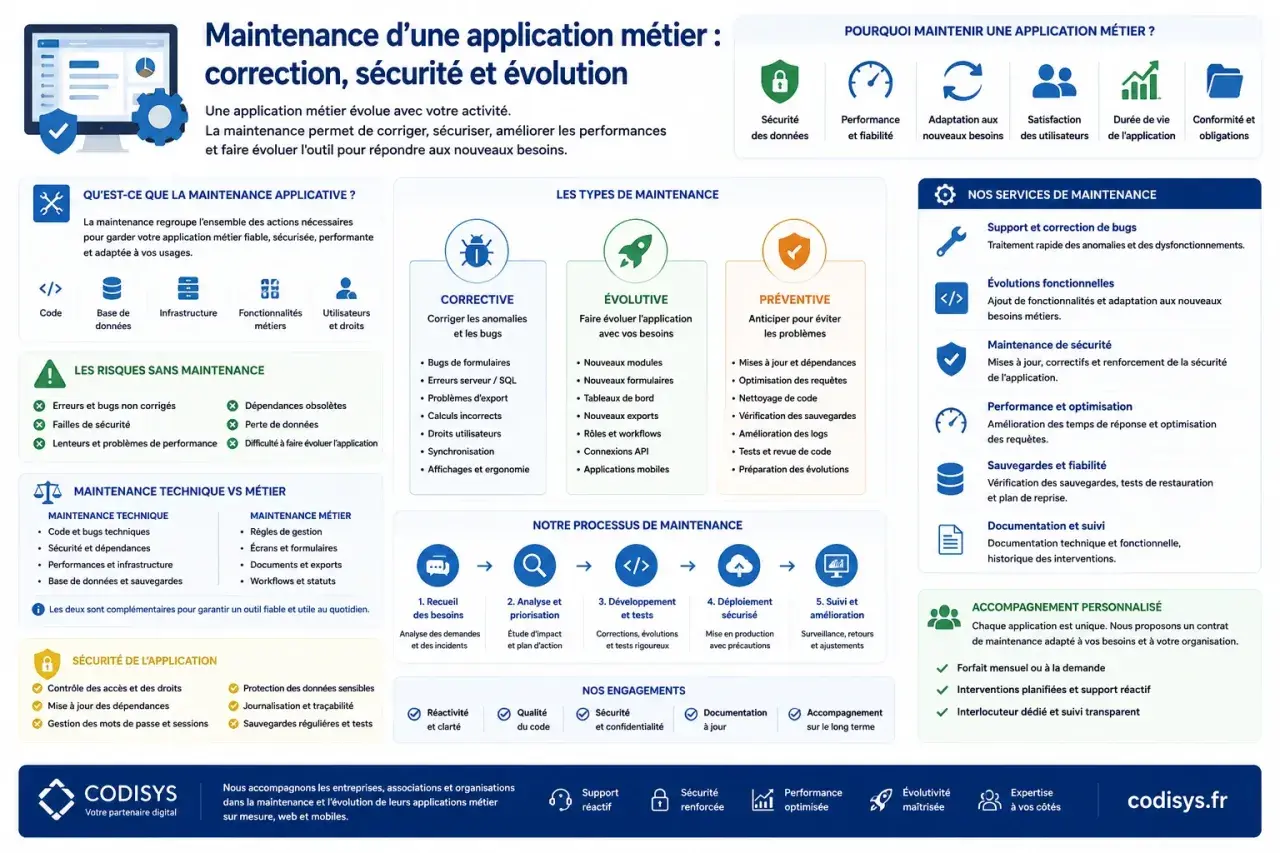
- La maintenance ne se limite pas aux bugs: elle couvre aussi les évolutions, la sécurité et la compatibilité.
- On distingue quatre familles utiles: corrective, adaptative, perfective et préventive.
- Le vrai coût se joue souvent dans le diagnostic, les tests de non-régression et les mises à jour de dépendances.
- Un bon process repose sur le triage, la priorisation, le rollback et la surveillance après mise en production.
- En France, la TMA reste un modèle courant, mais le choix interne, externe ou hybride dépend surtout du niveau de criticité et du savoir produit.
Ce que recouvre vraiment la maintenance d’une application
Je préfère penser la maintenance comme le travail qui permet à une application de rester vivante. On ne parle pas seulement de réparer des bugs, mais aussi de faire tenir ensemble le code, les dépendances, l’infrastructure, les usages métier et les exigences de sécurité. Dans beaucoup d’équipes françaises, on regroupe cela sous le terme TMA, surtout quand l’objectif est d’assurer le support opérationnel et les évolutions continues.
Concrètement, cette activité couvre plusieurs réalités très différentes: corriger une régression, adapter une application à une nouvelle version d’OS ou de navigateur, améliorer un parcours utilisateur, réduire les temps de réponse, ou encore préparer une montée de version technique. La nuance compte, car un incident de production ne se traite pas comme une demande d’amélioration fonctionnelle. Si l’on mélange tout, on perd vite en visibilité, en priorisation et en qualité de service.
Pour moi, la bonne question n’est jamais “faut-il maintenir ?”, mais plutôt “comment maintenir sans ralentir le produit”. C’est ce cadre qui permet ensuite de distinguer les différents types d’actions à mener.
Les quatre familles de maintenance à connaître
Quand j’analyse un backlog applicatif, je le classe presque toujours en quatre catégories. Cette grille simplifie les échanges entre produit, développement et exploitation, et elle aide aussi à expliquer pourquoi un même budget sert à des choses très différentes. La norme ISO/IEC/IEEE 14764 sert souvent de référence dans ce domaine, parce qu’elle donne une structure claire aux opérations de maintenance.
| Famille | Ce que ça couvre | Déclencheur typique | Exemple concret |
|---|---|---|---|
| Corrective | Correction d’un défaut ou d’un comportement erroné | Incident, bug, régression | Un formulaire ne valide plus correctement un champ après une mise à jour |
| Adaptative | Adaptation à un environnement qui change | Nouvelle version de navigateur, d’API, d’OS ou de dépendance | Mettre à jour une intégration de paiement après une évolution du prestataire |
| Perfective | Amélioration de l’existant | Besoin métier, retour utilisateur, optimisation | Raccourcir un tunnel d’achat ou fluidifier une recherche |
| Préventive | Réduction des risques futurs | Dette technique, fragilité détectée, obsolescence | Refactoriser un module trop couplé avant qu’il ne bloque les releases |
Dans les projets que je vois, la corrective attire toujours l’attention parce qu’elle est visible. Pourtant, la vraie charge vient souvent de l’adaptive et de la perfective: mises à jour de frameworks, adaptation aux changements métier, amélioration des performances, nettoyage du code. Autrement dit, la maintenance n’est pas seulement un centre de coût; c’est aussi un mécanisme de continuité et d’évolution. C’est précisément ce mélange qui rend l’organisation du quotidien si importante.
Comment se déroule une maintenance efficace au quotidien
Une maintenance bien tenue suit rarement l’improvisation. Je la vois plutôt comme une chaîne courte et disciplinée, où chaque étape évite de transformer un incident simple en problème durable. Plus le flux est clair, plus on réduit les délais de rétablissement et les effets de bord.
- Qualification du besoin ou de l’incident: est-ce un bug, une évolution, un sujet de sécurité ou une demande d’optimisation ?
- Reproduction et analyse d’impact: où le problème se manifeste-t-il, quelles versions sont touchées, quelles dépendances sont en cause ?
- Priorisation: un blocage métier ne passe pas dans la même file qu’un ajustement cosmétique.
- Correction ou changement, puis revue du code et tests de non-régression.
- Déploiement contrôlé avec possibilité de rollback, surtout sur les applications critiques.
- Surveillance post-release: logs, métriques, erreurs front, temps de réponse, retours utilisateurs.
Combien ça coûte vraiment et ce qui fait varier la facture
Les ordres de grandeur les plus cités dans la littérature et les retours d’expérience placent souvent la maintenance entre 50 % et 80 % du coût total du cycle de vie d’un logiciel. Ce n’est pas parce que tout coûte cher à maintenir; c’est surtout parce qu’une application vit longtemps, change souvent et doit rester compatible avec un environnement qui bouge sans cesse. Sur un produit mature, le coût principal n’est pas toujours la correction elle-même, mais le temps de diagnostic, de test et de sécurisation du changement.
Si je devais résumer les facteurs qui font monter la facture, je mettrais d’abord la complexité du code et la qualité de l’architecture. Une base mal découpée multiplie le risque de régression, rallonge les validations et ralentit chaque livraison. Ensuite viennent les dépendances externes, la couverture de tests, les contraintes réglementaires, les horaires de support et le niveau de disponibilité attendu. Une application exposée 24/7 avec engagement de reprise rapide n’a évidemment pas le même coût qu’un outil interne utilisé en journée.
| Facteur | Impact sur le coût | Ce que je regarde en priorité |
|---|---|---|
| Architecture monolithique ou très couplée | Fort | Temps de propagation des changements et risque de régression |
| Couverture de tests faible | Fort | Nombre de corrections qui nécessitent des vérifications manuelles |
| Dépendances externes nombreuses | Moyen à fort | Rythme des mises à jour et risque de cassure d’intégration |
| Exigence de disponibilité élevée | Fort | SLA, astreintes, observabilité et capacité de rollback |
| Documentation faible | Moyen à fort | Temps perdu à comprendre l’existant et à reproduire les incidents |
Je conseille de raisonner en coût récurrent plutôt qu’en simple budget de correction. Une application “bon marché” à construire peut devenir très chère à exploiter si elle n’a pas été pensée pour évoluer. C’est ce constat qui mène naturellement à une autre décision: faut-il garder la maintenance en interne, la confier à un prestataire ou adopter un modèle hybride ?
Interne, TMA ou hybride, comment choisir le bon modèle
En France, le choix ne se réduit pas à “on garde tout” ou “on sous-traite tout”. Dans la pratique, le meilleur modèle est souvent celui qui protège la connaissance métier tout en absorbant les pics de charge et les tâches répétitives. Pour y voir clair, je compare toujours les options selon trois critères: maîtrise fonctionnelle, vitesse d’exécution et capacité à absorber les incidents.
| Modèle | Atouts | Limites | À privilégier quand |
|---|---|---|---|
| Équipe interne | Bonne connaissance du produit, arbitrages rapides, continuité forte | Coût de staffing, dépendance aux compétences rares | L’application est stratégique et évolue vite |
| TMA externalisée | SLA formalisés, capacité de prise en charge, flexibilité | Risque de perte de contexte, besoin de cadrage précis | Le support est stable, documenté et à volume prévisible |
| Hybride | Bon compromis entre expertise produit et exécution | Nécessite une gouvernance propre et des interfaces claires | Le produit est critique mais l’équipe doit rester agile |
Les pratiques qui réduisent les incidents avant qu’ils coûtent cher
La meilleure maintenance reste celle qu’on n’a pas besoin d’improviser. Je vois une vraie différence entre les équipes qui subissent leurs releases et celles qui les préparent méthodiquement. Les secondes n’ont pas moins de changements; elles ont surtout des changements plus petits, mieux observés et plus faciles à revenir en arrière.- Automatiser les tests de non-régression: chaque correctif doit prouver qu’il n’a pas cassé le reste du système.
- Instrumenter l’application: logs structurés, métriques, traces et alertes utiles, pas seulement du bruit.
- Versionner proprement les dépendances: cela évite les mises à jour subies et les surprises de compatibilité.
- Documenter les runbooks: en cas d’incident, une procédure claire fait gagner des heures.
- Découper les déploiements: petits lots, feature flags, validation progressive.
- Prévoir le rollback: si la release échoue, revenir en arrière doit être une opération normale, pas une improvisation héroïque.
- Mesurer les bons indicateurs: MTTR, taux d’échec des changements, volume d’incidents récurrents et délai de correction.
Le MTTR, pour mean time to recover, désigne le temps moyen nécessaire pour rétablir un service. C’est un indicateur que je regarde de près, parce qu’il dit beaucoup plus sur la robustesse réelle d’un support que le simple nombre de tickets traités. Si le rétablissement est long, le problème n’est pas toujours le bug lui-même; il peut venir d’un manque d’observabilité, d’une architecture fragile ou d’un process de déploiement trop brut.
Les erreurs qui font dériver un support applicatif
Les dérives les plus coûteuses ne viennent pas toujours des grosses pannes. Elles apparaissent souvent dans les petites habitudes: un correctif poussé sans test, une dépendance laissée trop longtemps de côté, un ticket urgent traité sans analyse d’impact, ou une connaissance trop concentrée sur une seule personne. À la longue, ces choix créent un système qui semble fonctionner, mais qui devient de plus en plus difficile à faire évoluer.
Je vois souvent les mêmes pièges revenir:
- confondre urgence et priorité, ce qui épuise l’équipe et brouille le backlog;
- reporter les mises à jour techniques jusqu’au moment où elles deviennent risquées;
- négliger la documentation, puis perdre des heures à redécouvrir l’existant;
- sortir des correctifs trop gros, trop espacés et trop difficiles à valider;
- ne pas isoler les responsabilités entre support, produit et développement;
- attendre une grande refonte pour régler des problèmes qui se résolvent mieux par petites améliorations continues.
Mon avis est simple: la maintenance devient chère quand elle est subie. Dès qu’un produit est gouverné avec des releases régulières, des tests fiables et une lecture claire des incidents, le coût reste maîtrisable et la qualité suit. Dès qu’on accumule les exceptions, le support se transforme en rattrapage permanent.
Ce qu’il faut garder en tête avant de réorganiser le support de vos applications
Si je devais résumer l’approche la plus saine, je dirais ceci: classez d’abord vos applications par criticité, clarifiez le type d’interventions attendu, puis choisissez un modèle de support qui correspond réellement à votre rythme de changement. Une application métier stable n’a pas besoin de la même mécanique qu’un produit web en évolution continue.
Ensuite, ne laissez pas le support vivre à côté du développement. Les deux sujets sont liés, et c’est souvent la qualité du passage en production qui décide du coût réel sur la durée. Une équipe qui sait diagnostiquer vite, tester proprement et revenir en arrière sans panique gagne presque toujours en fiabilité, en sérénité et en budget.
Au fond, une bonne maintenance ne sert pas seulement à réparer: elle protège la vitesse de livraison et la crédibilité du produit. C’est ce qui fait la différence entre une application qui survit et une application qui reste utile, stable et évolutive dans le temps.