
Quand on travaille avec MySQL, la vraie difficulté n’est pas de mémoriser trois commandes, mais d’écrire des requêtes qui renvoient la bonne donnée, au bon format, sans ambiguïté. Dans cet article, je reprends la logique de SQL dans MySQL, les requêtes qui servent vraiment au quotidien, les jointures, les agrégations et les réflexes de performance qui évitent de transformer une base saine en source de problèmes. Je termine avec les choix de version qui comptent en 2026 pour garder un socle stable et maintenable.
Les points à retenir pour travailler efficacement avec MySQL
- SQL est le langage, MySQL est le SGBD qui l’exécute et applique ses propres règles de comportement.
- Les clauses qui reviennent sans cesse sont `SELECT`, `WHERE`, `JOIN`, `GROUP BY`, `HAVING`, `ORDER BY` et `LIMIT`.
- En MySQL, garder `ONLY_FULL_GROUP_BY` activé évite des résultats aléatoires dans les requêtes d’agrégation.
- Pour la performance, je regarde d’abord les index, puis le plan d’exécution avec `EXPLAIN` ou `EXPLAIN ANALYZE`.
- En 2026, MySQL 8.0 est arrivé en fin de vie, donc je privilégie 8.4 LTS pour un environnement de production.
SQL et MySQL, ce que je distingue avant d’écrire une requête
Je commence toujours par cette distinction, parce qu’elle évite beaucoup de confusions. SQL est le langage de requête, tandis que MySQL est le système de gestion de base de données relationnelle qui interprète ces requêtes, stocke les données, gère les index et applique des règles de validation. Autrement dit, on écrit en SQL, mais on négocie avec le comportement spécifique de MySQL.Cette différence compte dès qu’on passe de la théorie à la pratique. Une requête peut être syntaxiquement correcte en SQL, puis produire un résultat inattendu dans MySQL à cause d’un mode SQL, d’un `JOIN` mal placé ou d’un regroupement ambigu. Dans un SI, ce n’est pas un détail académique, c’est une source directe d’erreurs métier si l’on ne fait pas attention.
| Notion | Ce que c’est | Impact concret |
|---|---|---|
| SQL | Le langage utilisé pour interroger et modifier les données | Je décris ce que je veux obtenir, pas la mécanique de stockage |
| MySQL | Le moteur qui exécute le langage et organise les données | Le résultat dépend aussi des réglages et des optimisations du serveur |
| Schéma | La structure des tables, colonnes, clés et relations | Il détermine la qualité des jointures et la cohérence des données |
| Requête | Une instruction SQL précise | Elle peut lire, écrire, modifier ou supprimer des lignes |
Une fois ce cadre posé, je peux passer aux requêtes qui servent vraiment au quotidien, parce que c’est là que la valeur pratique devient visible.
Les requêtes de base qui font 80 % du travail
Dans la plupart des projets, je reviens sans cesse aux mêmes blocs de construction. `SELECT` choisit les colonnes, `FROM` désigne la table source, `WHERE` filtre les lignes, `ORDER BY` trie le résultat et `LIMIT` borne la quantité de données renvoyées. C’est simple sur le papier, mais c’est précisément cette simplicité qui permet d’écrire des requêtes propres et faciles à maintenir.
SELECT id, nom, ville
FROM clients
WHERE statut = 'actif'
ORDER BY nom
LIMIT 20;Ici, je demande une liste courte de clients actifs, triée par nom. Ce type de requête est utile pour une interface, un export ou un contrôle rapide, et il montre bien pourquoi je préfère sélectionner seulement les colonnes utiles plutôt que de faire un `SELECT *` par réflexe.
Quand il faut écrire ou mettre à jour une donnée, je garde la même discipline, surtout sur les requêtes mutantes. `INSERT`, `UPDATE` et `DELETE` doivent rester explicites, avec un filtre clair quand la modification ne concerne pas toute la table. En pratique, une absence de `WHERE` sur un `UPDATE` ou un `DELETE` reste l’une des erreurs les plus coûteuses qu’on peut faire dans un SI.
- `SELECT` pour lire.
- `INSERT` pour ajouter.
- `UPDATE` pour corriger.
- `DELETE` pour supprimer.
Quand les lignes viennent de plusieurs tables, le sujet devient celui des jointures, et c’est souvent là que les requêtes commencent à révéler leur vraie complexité.
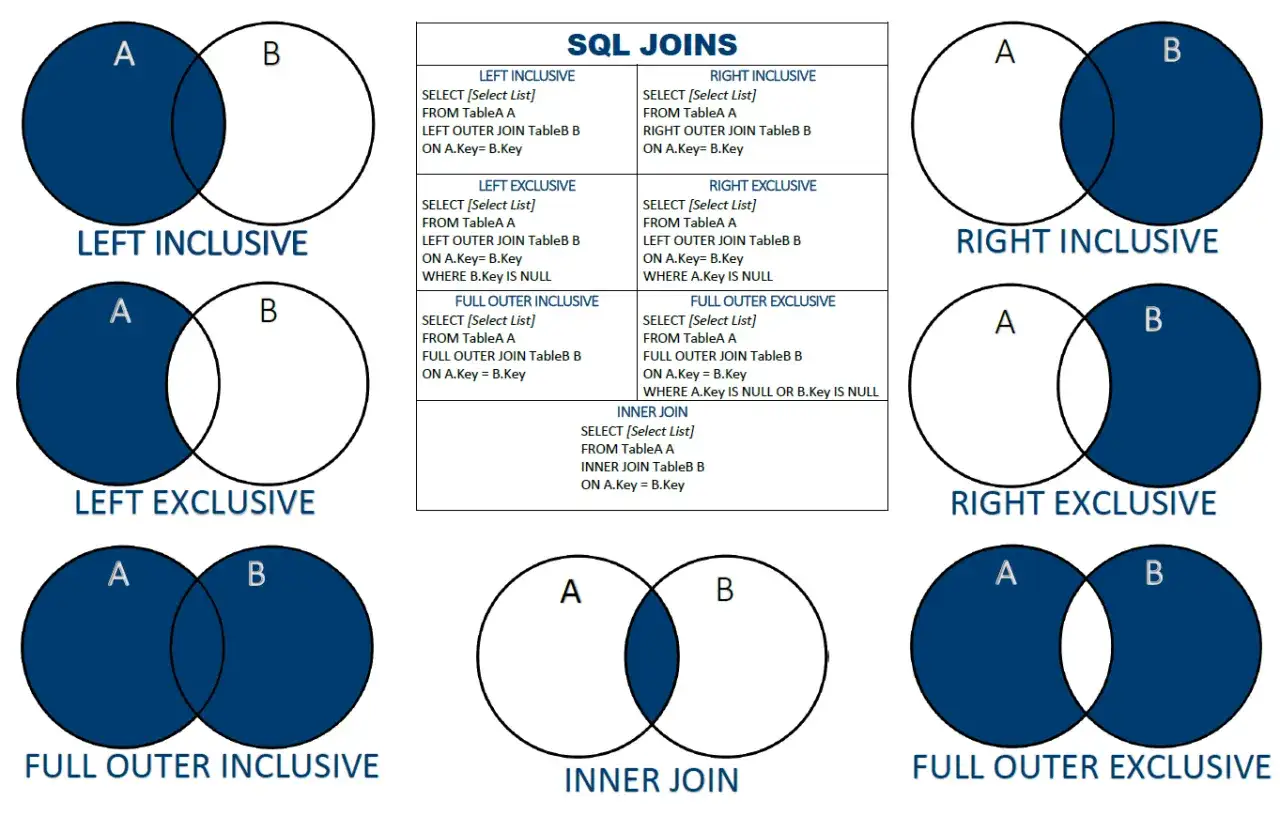
Joindre les tables sans brouiller le sens des données
Dans une base relationnelle, les tables vivent rarement seules. Je relie presque toujours une table de faits, comme `commandes`, à une table de référence, comme `clients` ou `produits`. MySQL gère ces relations avec des jointures, et c’est là qu’on voit très vite si le modèle de données est propre ou non.
La jointure la plus fréquente reste `INNER JOIN`, parce qu’elle ne garde que les lignes qui ont une correspondance des deux côtés. `LEFT JOIN`, lui, conserve toutes les lignes de la table de gauche, même s’il n’existe pas de correspondance. J’utilise souvent ce deuxième cas pour détecter des absences, des anomalies ou des fiches incomplètes.
| Type de jointure | Ce qu’elle renvoie | Quand je l’utilise |
|---|---|---|
| `INNER JOIN` | Uniquement les correspondances | Quand je veux relier deux tables et ne garder que les enregistrements complets |
| `LEFT JOIN` | Toutes les lignes de gauche, avec les correspondances à droite si elles existent | Quand je veux conserver les entités même sans relation enfant |
| `RIGHT JOIN` | L’inverse du `LEFT JOIN` | Je l’utilise rarement, car je préfère garder une lecture de gauche à droite plus naturelle |
SELECT c.nom, o.numero, o.total
FROM clients c
INNER JOIN commandes o
ON o.client_id = c.id;Ce schéma répond à une question simple: quels clients ont passé quelles commandes? Le `ON` définit la relation, et c’est une différence importante avec `WHERE`, qui sert à filtrer le résultat final. Si je place un filtre sur la table de droite d’un `LEFT JOIN` dans `WHERE`, je peux transformer sans le vouloir ma jointure externe en jointure interne, ce qui fait disparaître les lignes sans correspondance.
SELECT c.nom, o.numero
FROM clients c
LEFT JOIN commandes o
ON o.client_id = c.id
AND o.date_commande >= '2026-01-01';Je préfère mettre la contrainte de date dans `ON` ici, parce que je veux garder les clients même s’ils n’ont pas encore commandé sur la période. C’est une petite nuance de syntaxe, mais elle change complètement le sens métier du résultat. Une fois les lignes réunies, je passe aux totaux et aux indicateurs, parce que c’est souvent ce que l’on demande ensuite dans un tableau de bord ou un reporting.
Regrouper et filtrer les agrégats sans pièges
Les agrégations sont le cœur des usages analytiques. `COUNT`, `SUM`, `AVG`, `MIN` et `MAX` me permettent de transformer des lignes brutes en indicateurs lisibles. Là encore, la nuance entre `WHERE` et `HAVING` est essentielle: `WHERE` filtre avant le regroupement, alors que `HAVING` agit après.
SELECT c.nom,
COUNT(o.id) AS nb_commandes,
SUM(o.total) AS chiffre_affaires
FROM clients c
JOIN commandes o ON o.client_id = c.id
WHERE o.date_commande >= '2026-01-01'
GROUP BY c.nom
HAVING COUNT(o.id) >= 5
ORDER BY chiffre_affaires DESC;Dans cet exemple, je ne garde que les clients qui ont au moins cinq commandes sur la période. `WHERE` réduit d’abord le volume de données, `GROUP BY` construit les groupes, puis `HAVING` filtre les groupes finaux. Cette logique évite des requêtes incohérentes et rend le code plus lisible pour quelqu’un d’autre dans l’équipe.
| Clause | Rôle | Erreur fréquente |
|---|---|---|
| `WHERE` | Filtrer les lignes avant agrégation | Essayer d’y mettre une condition sur `COUNT()` ou `SUM()` |
| `GROUP BY` | Construire les groupes à agréger | Oublier d’y mettre les colonnes de regroupement réellement nécessaires |
| `HAVING` | Filtrer les groupes après calcul | Le détourner pour des conditions qui devraient rester dans `WHERE` |
Je garde aussi `ONLY_FULL_GROUP_BY` activé. Ce mode me protège contre les requêtes ambiguës qui pourraient renvoyer une valeur arbitraire dans un groupe, ce qui est presque toujours une mauvaise surprise en production. Si une requête échoue à cause de ce mode, je préfère corriger la logique plutôt que désactiver la règle. Quand la requête est juste, je regarde ensuite comment MySQL l’exécute réellement, parce que la lisibilité ne suffit pas toujours à garantir la vitesse.
Écrire des requêtes lisibles et performantes au quotidien
Quand une requête devient lente, je ne commence pas par deviner. J’utilise `EXPLAIN` pour comprendre comment MySQL lit les tables, dans quel ordre il les joint et s’il utilise un index. Si j’ai besoin de mesurer le temps réel, `EXPLAIN ANALYZE` me donne une image plus concrète du coût d’exécution.
En optimisation, il y a quelques réflexes qui donnent souvent les meilleurs résultats avant même de toucher au schéma. Je les applique systématiquement, parce qu’ils évitent beaucoup de bruit inutile dans les revues de performance.
- Indexer les colonnes utilisées dans `WHERE`, `JOIN` et `ORDER BY` quand le volume le justifie.
- Éviter les fonctions sur une colonne indexée dans une clause de filtrage.
- Limiter les colonnes retournées au strict nécessaire.
- Se méfier des grands `OFFSET` pour la pagination, surtout sur des tables volumineuses.
- Vérifier qu’un `LIKE` reste exploitable par index, par exemple avec un préfixe clair.
-- Moins efficace
SELECT id, total
FROM commandes
WHERE DATE(date_commande) = '2026-06-27';
-- Plus exploitable par un index sur date_commande
SELECT id, total
FROM commandes
WHERE date_commande >= '2026-06-27'
AND date_commande < '2026-06-28';Ce genre de correction semble mineur, mais il change souvent le plan d’exécution de façon spectaculaire. Je le vois régulièrement sur des bases de production où la requête était écrite pour être simple à lire, mais pas pour être efficace à grande échelle. Le dernier point, plus stratégique, concerne la version de MySQL elle-même, car les choix de cycle de vie changent la manière dont on prépare une base.
Quelle version de MySQL je privilégie en 2026
En 2026, je ne traiterais pas toutes les branches MySQL de la même façon. Selon les notes de version MySQL, MySQL 8.0 est arrivé en fin de vie en avril 2026, donc je ne le choisirais plus pour un nouveau projet. Pour un SI qui doit durer, je privilégie MySQL 8.4 LTS, et je réserve les versions Innovation aux contextes de test, d’évaluation ou de veille technique.
| Track | Quand je le choisis | Force principale | Réserve |
|---|---|---|---|
| 8.4 LTS | Production, SI, socle stable | Comportement plus prévisible, support plus long | Moins orienté nouveautés rapides |
| 9.x Innovation | Tests, prototypes, expérimentation | Accès plus rapide aux évolutions | Évolutions comportementales plus fréquentes |
Le document de MySQL sur les releases précise aussi qu’une branche LTS suit un cycle de support plus long, avec des corrections de bugs et de sécurité sans changements brutaux de comportement. C’est exactement ce que je recherche quand une base alimente des applications, des tableaux de bord ou des flux métier sensibles. Si un projet tourne encore sur 8.0, je planifie la migration plutôt que de la repousser, parce qu’une base en fin de support devient vite un risque opérationnel inutile.
Le réflexe que j’applique avant de pousser une requête en production
Avant de valider une requête, je me pose toujours la même série de questions simples, parce qu’elles capturent l’essentiel du risque. Est-ce que le filtre est au bon endroit? Est-ce que la jointure conserve bien les lignes attendues? Est-ce que l’agrégation est déterministe? Est-ce que le plan d’exécution ressemble à ce que j’imaginais?
- J’écris d’abord la version la plus simple possible.
- Je teste le résultat sur un jeu de données crédible, pas seulement sur trois lignes.
- Je regarde le plan avec `EXPLAIN` avant de discuter de performance.
- Je garde les modes de sécurité utiles, notamment `ONLY_FULL_GROUP_BY`.
- Je choisis la version de MySQL en fonction du cycle de support, pas de la nouveauté.
Si je ne devais retenir qu’une habitude, ce serait celle-ci: commencer simple, vérifier le plan, puis ajouter de la complexité seulement quand elle répond à un besoin réel. C’est cette discipline qui transforme MySQL en outil de fiabilité pour les données et le SI, pas seulement en moteur qui stocke des tables.