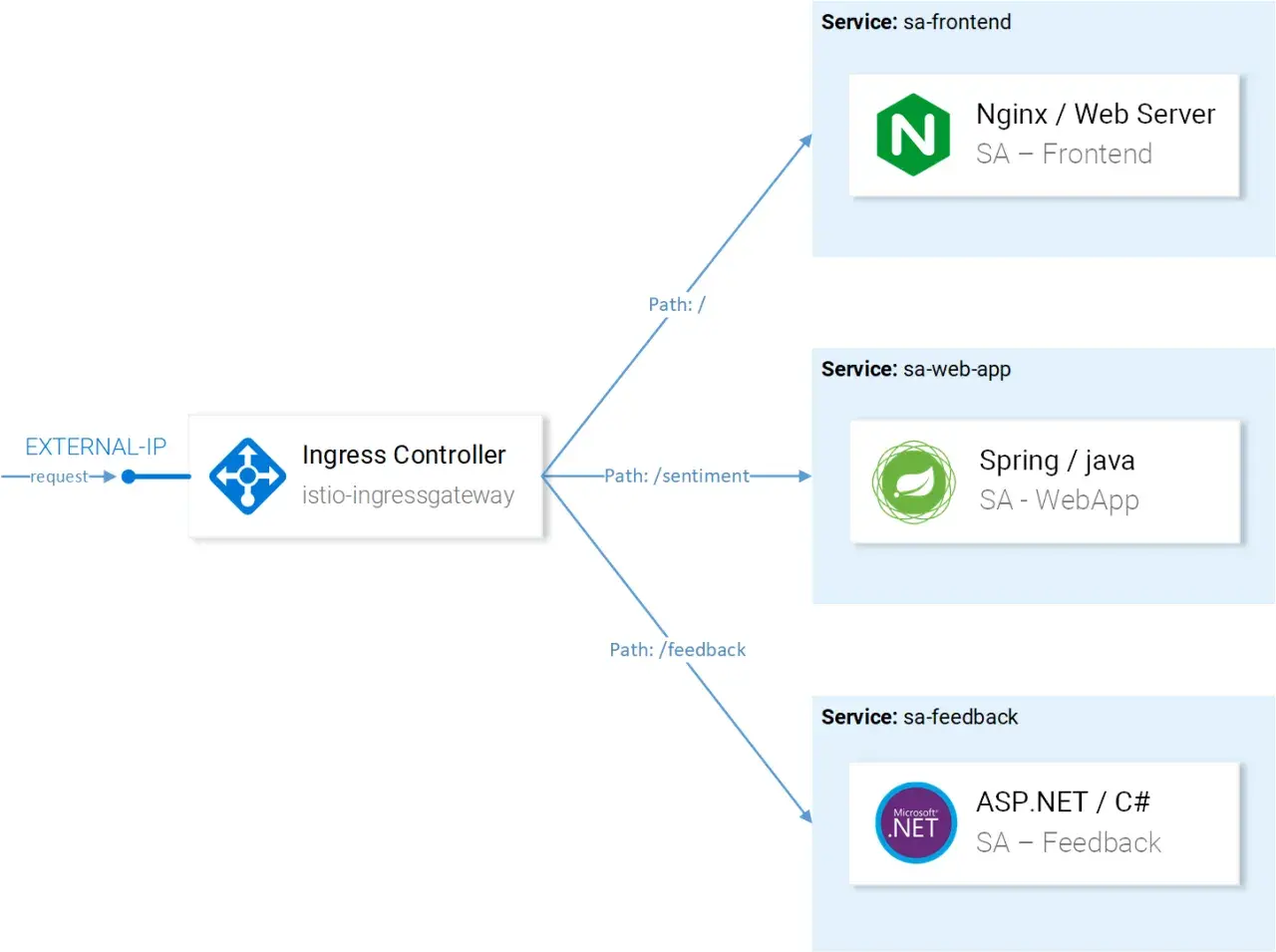
Dans Istio, le routage ne se résume pas à envoyer une requête vers un service au hasard. Il s’agit de décider, avec précision, quelle version reçoit le trafic, selon quels critères, et avec quels garde-fous pour limiter les erreurs en production. La ressource VirtualService est l’endroit où je pose ces règles, que ce soit pour un split canary, un routage par en-tête, une redirection d’URL ou un trafic d’entrée via gateway, sur Kubernetes comme sur Azure AKS.
Les points essentiels à garder en tête avant de configurer le routage
- Une VirtualService décrit des règles de routage, pas la mécanique de déploiement des pods.
- Les règles sont évaluées dans l’ordre et reposent sur des critères de match très précis.
- DestinationRule complète le dispositif en définissant les subsets et les politiques appliquées après le routage.
- Les usages les plus utiles restent le canary, l’A/B testing, le routage par identité et la gestion ingress/egress.
- Sur AKS, le cadre de support Microsoft influence le choix des fonctionnalités avancées.
Ce que fait vraiment une VirtualService
La VirtualService est la couche qui dit à Istio comment diriger une requête une fois qu’un hôte est visé. Elle ne crée pas les services et ne remplace pas Kubernetes : elle ajoute une logique de trafic au-dessus des services existants. Dans la pratique, je la vois comme une table de décision déclarative qui relie un nom de service à une destination réelle, parfois un sous-ensemble précis de ce service, parfois un autre service entièrement différent.
La documentation Istio insiste sur un point utile à garder en tête : les règles peuvent cibler un protocole donné, tenir compte de la source du trafic, et router vers plusieurs destinations selon le contexte. C’est ce qui rend la ressource si intéressante pour piloter des versions applicatives sans toucher au code. Un client continue d’appeler le même point d’entrée, tandis que la mesh choisit en interne où envoyer la requête.
Je recommande de penser la VirtualService en trois blocs mentaux simples :
- le point d’entrée avec `hosts`, c’est-à-dire le nom ou les noms adressables par le client ;
- les conditions avec `match`, qui filtrent selon l’URI, les en-têtes, le schéma, la méthode ou la source ;
- la sortie avec `route`, qui indique la destination finale.
Autrement dit, la VirtualService répond à une question très concrète : « dans cette situation précise, vers quelle version ou quel service dois-je envoyer le trafic ? » Pour comprendre comment Istio prend cette décision, il faut maintenant regarder la mécanique de match et de priorité des règles.
Comment Istio choisit la bonne destination
Istio évalue les règles de routage dans l’ordre. Dès qu’une règle correspond, elle s’applique, ce qui veut dire qu’un mauvais ordre peut produire un résultat différent de celui que vous aviez en tête. C’est un détail technique, mais c’est souvent là que les premières confusions apparaissent en environnement réel.
| Champ | Rôle | Ce que je vérifie en priorité |
|---|---|---|
hosts |
Définit les destinations virtuelles visées par la règle | Que le nom corresponde bien au service attendu, idéalement en FQDN quand le contexte grossit |
match |
Filtre les requêtes selon l’URI, les en-têtes, la méthode, le schéma ou la source | Que les conditions soient assez précises pour éviter les collisions |
route |
Pointe vers la destination réelle, souvent un subset | Que la destination existe et que les labels soient cohérents |
gateways |
Limite la portée de la règle à certains gateways | Que le trafic interne et externe soient bien séparés |
timeout / retries
|
Ajoute des garde-fous de résilience | Que ces valeurs restent compatibles avec le comportement de l’application |
Deux règles de lecture sont particulièrement importantes. Premièrement, à l’intérieur d’un même bloc match, les conditions sont combinées en AND : tout doit correspondre. Deuxièmement, plusieurs blocs match dans une même règle fonctionnent en OR : un seul bloc qui matche suffit. Cette logique permet de construire des scénarios très fins sans multiplier inutilement les objets Kubernetes.
Je fais aussi attention au champ gateways. Quand une VirtualService doit s’appliquer au trafic interne de la mesh, il faut penser à la portée correcte, et le gateway réservé mesh devient alors un repère important. En pratique, je préfère des noms explicites et je réserve les noms courts aux environnements très maîtrisés, parce qu’un cluster avec plusieurs namespaces pardonne rarement l’approximation.
Une fois cette mécanique claire, le duo avec DestinationRule devient beaucoup plus lisible.
Le rôle complémentaire de DestinationRule
VirtualService décide où envoyer le trafic. DestinationRule décide comment ce trafic doit être traité une fois la destination choisie. La différence est essentielle, et je conseille de ne pas les fusionner dans la tête, sinon on finit par chercher le mauvais réglage au mauvais endroit.
La ressource DestinationRule sert notamment à définir des subsets, souvent alignés sur des versions d’application. C’est elle qui donne une structure exploitable aux routes de la VirtualService. Sans subsets bien définis, un split vers `v1`, `v2` ou `v3` perd une grande partie de son intérêt.
apiVersion: networking.istio.io/v1
kind: DestinationRule
metadata:
name: reviews
spec:
host: reviews.prod.svc.cluster.local
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
trafficPolicy:
loadBalancer:
simple: LEAST_REQUESTCe type de configuration permet de séparer proprement les responsabilités. La VirtualService choisit la version ou le chemin, puis DestinationRule applique le comportement réseau associé au service réel : load balancing, taille de pool de connexions, détection d’instances défaillantes. C’est propre, réutilisable et beaucoup plus simple à maintenir qu’une logique de routage dispersée dans plusieurs couches.
Je retiens surtout un point pratique : les réglages de résilience ne remplacent pas la robustesse applicative. Si votre application impose déjà un timeout de 2 secondes et que vous poussez un timeout de 3 secondes dans la mesh, l’application passera avant la couche réseau. Istio donne de la souplesse, mais il ne corrige pas les hypothèses contradictoires. C’est précisément pour cela qu’il faut regarder maintenant les usages qui apportent un vrai gain métier.
Les cas d’usage qui apportent un vrai gain
Quand on utilise bien la VirtualService, on gagne surtout en contrôle progressif. Je vois quatre scénarios revenir très souvent, et ce sont eux qui justifient le plus clairement cette abstraction.
Déployer un canary sans casser la lecture du trafic
Le canary consiste à envoyer une petite part du trafic vers une nouvelle version, puis à augmenter progressivement cette part si les signaux restent bons. Un split 80/20 est un bon exemple de départ, mais ce n’est qu’un exemple : l’idée est de rendre le basculement mesurable, pas brutal. C’est utile quand vous voulez voir si la nouvelle version encaisse la charge, si les erreurs montent, ou si les temps de réponse dérivent.
Faire de l’A/B testing proprement
Dans un test A/B, la VirtualService peut router selon l’identité de l’utilisateur, un header, une URI ou un segment de trafic précis. J’aime ce modèle parce qu’il évite de mélanger logique produit et logique de distribution. Le service continue à fonctionner normalement, mais une partie contrôlée des utilisateurs est exposée à un comportement différent. C’est un bon moyen de tester une fonctionnalité ou une UX sans multiplier les branches de code côté application.
Isoler des parcours internes et externes
La même logique sert aussi pour les entrées et sorties de mesh. Couplée à un gateway, la VirtualService peut filtrer ce qui entre dans le cluster. Avec un ServiceEntry, elle peut également diriger du trafic vers une dépendance externe, ce qui est très utile quand une application consomme des services hors mesh mais que l’on veut garder une politique de routage centralisée.
Lire aussi : Azure Event Hubs - Votre guide complet pour des flux parfaits
Garder un comportement prévisible pendant une migration
C’est probablement le cas le plus sous-estimé. Quand vous découpez un monolithe en microservices, la VirtualService permet de maintenir une façade stable pour les consommateurs. Les clients continuent d’appeler le même hôte, mais le backend se réorganise en coulisse. C’est une approche beaucoup plus saine qu’une migration visible d’un seul bloc, surtout quand plusieurs équipes dépendent du service.
Ces scénarios prennent tout leur sens si la plateforme sur laquelle vous travaillez n’ajoute pas de contraintes cachées. C’est là qu’Azure et l’add-on Istio d’AKS changent un peu la donne.
Ce que l’on doit vérifier sur AKS et Microsoft Azure
Sur Azure Kubernetes Service, Microsoft fournit un add-on Istio officiellement supporté et testé. C’est rassurant pour une équipe qui veut éviter la charge d’une installation entièrement auto-gérée, surtout si l’objectif est de rester dans une trajectoire opérationnelle claire. En revanche, ce confort a un prix : certaines personnalisations sont plus encadrées que dans un Istio open source installé manuellement.
Je résume la situation de façon très pragmatique :
| Contexte | Ce qui marche bien | Point d’attention |
|---|---|---|
| AKS avec add-on Istio | Routage standard, ingress vérifié, support Microsoft | Certaines ressources et options restent limitées ou non prises en charge |
| Istio auto-géré sur AKS | Plus de liberté de configuration | Vous gérez vous-même l’exploitation, les mises à jour et les arbitrages de support |
| Besoin de fonctionnalités très avancées | À valider au cas par cas | Ambient, multi-cluster ou certaines intégrations demandent une vérification préalable |
Microsoft précise aussi que l’add-on ne prend pas encore en charge certaines capacités comme le mode Ambient, le multi-cluster, ni la gestion mesh via Gateway API dans son périmètre actuel. Pour être direct, si votre feuille de route dépend de ces options, je ne construirais pas une architecture en partant du principe qu’elles seront disponibles immédiatement dans l’add-on géré. Il vaut mieux l’anticiper avant de figer les manifests.
Mon approche, sur AKS, est simple : je reste sur les primitives Istio qui ont une valeur sûre pour le routage, je teste le comportement réel des routes dans le cluster, et je valide le support avant d’introduire des fonctionnalités plus exotiques. C’est moins spectaculaire qu’un design très ambitieux, mais beaucoup plus robuste. Une fois ce cadre posé, il reste à éviter les pièges les plus fréquents.
Les erreurs que je vois le plus souvent
La majorité des incidents autour d’une VirtualService ne viennent pas d’Istio lui-même, mais d’un décalage entre l’intention et la déclaration YAML. Voilà les fautes que je rencontre le plus souvent.
- Oublier la DestinationRule associée alors que la VirtualService cible des subsets. La route pointe alors vers une destination mal définie ou incomplète.
- Mettre des règles dans le mauvais ordre. Comme Istio évalue les routes séquentiellement, une règle trop générale placée avant une règle précise peut neutraliser cette dernière.
- Utiliser des hosts trop ambigus. Un nom court peut être pratique, mais dans un cluster multi-namespace il devient vite source de confusion.
- Multiplier les regex inutiles. C’est tentant, mais cela rend la configuration plus fragile et plus difficile à relire.
- Confondre timeout applicatif et timeout de mesh. Si l’application coupe avant la mesh, la politique Istio ne change pas le résultat.
- Ne pas prévoir de route par défaut. Dans un contexte de canary ou d’identité, il faut toujours savoir où va le trafic non ciblé explicitement.
Il y a aussi un effet de bord qu’il faut connaître : quand tous les pods d’un pool de charge sont indisponibles, Envoy peut renvoyer un HTTP 503. Ce n’est pas un bug mystérieux, c’est le symptôme d’une destination qui n’a plus de backend sain. Dans ce cas, la bonne question n’est pas seulement « pourquoi la route échoue ? », mais aussi « quelle logique de fallback l’application doit-elle prévoir ? »
Je passe systématiquement par une vérification simple avant mise en production : la destination existe-t-elle vraiment, le subset est-il bien labelisé, la règle de fallback est-elle claire, et le timeout correspond-il au comportement attendu du service ? Si ces quatre points tiennent, le reste devient nettement plus fiable.
Ce que je vérifie avant de passer la règle en production
Avant de considérer une configuration comme prête, je la teste avec une logique de service, pas uniquement avec une logique YAML. Je veux voir le trafic réel, la version réellement atteinte, et le comportement quand la version cible tombe ou ralentit. C’est souvent à ce moment-là que l’on découvre si le routage est vraiment maîtrisé ou seulement correct sur le papier.
- Le host est-il stable et sans ambiguïté pour les clients et les namespaces concernés ?
- Les conditions de match sont-elles assez précises pour éviter les collisions de routes ?
- Les subsets de DestinationRule correspondent-ils bien aux labels réellement déployés ?
- Le split de trafic est-il lisible et réversible si une version nouvelle dégrade le service ?
- Les timeouts et retries sont-ils compatibles avec les délais de l’application et des dépendances ?
- Sur AKS, ai-je vérifié que la fonctionnalité visée est bien compatible avec le support du moment ?
Si je devais résumer la méthode en une phrase, je dirais ceci : la VirtualService vous donne le volant, DestinationRule vous donne la tenue de route, et la plateforme impose le cadre de conduite. Bien utilisée, cette combinaison rend le trafic plus prévisible, les déploiements plus sûrs et les migrations plus lisibles. C’est exactement ce que j’attends d’une bonne configuration de routage dans Istio.